Happy New Year 2025
Another amazing New Year's Eve firework from Sydney. I especially like the drum and bass finale 🥳
Another amazing New Year's Eve firework from Sydney. I especially like the drum and bass finale 🥳
Golang caches downloaded modules including unpacked source code of versioned dependencies in $GOPATH/pkg/mod.
Naturally this cache grows over time.
It can be cleaned up with the following command:
go clean -modcache
Just completed the earlier announced backfilling of screenshots from the Internet Archive.
Overall there are now screenshots from the last 22 years split over 4 domains, multiple CSS layouts and blogging systems.
In addition to the already mentioned articles, I did optimize the resulting PNG files with oxipng to reduce their size.
Enjoy sifting through the past visuals of the blog 🎉
Text fragments allow linking to any text on a page, not limited to <a name="anchorname"> anchors or elements with an id="anchorname" attribute.
To achieve this it introduces the special #:~:text=... prefix which browsers recognize and navigate to the text on a page.
https://example.com#:~:text=[prefix-,]textStart[,textEnd][,-suffix]
The simplest case is to just use textStart:
https://blog.x-way.org/Misc/2024/12/27/Scheduled-Screenshots.html#:~:text=GitHub%20Action
By using the textEnd we can link to a whole section of a text:
https://blog.x-way.org/Misc/2024/12/27/Scheduled-Screenshots.html#:~:text=steps,per%20month
And with prefix- and -suffix we can further control the exact location when there are multiple matches:
https://blog.x-way.org/Misc/2024/12/27/Scheduled-Screenshots.html#:~:text=blog-,screenshots
https://blog.x-way.org/Misc/2024/12/27/Scheduled-Screenshots.html#:~:text=screenshots,-repo
There is also a corresponding CSS pseudo-element which can be used to style the linked to text fragment on a page:
::target-text { background-color: red; }
(via)
Alex explains in this article how to automatically take regular screenshots of their website.
The automation happens with a GitHub Action that uses Playwright to take the screenshots and then stores them in the Git repository.
Alex has made the repo public, thus we can have a look at how this is implemented.
I followed the steps listed in their repo and did setup my own scheduled screenshots repo.
It will now take some screenshots of my blog once per month.
A project for the future will be to leverage the Internet Archive to backfill my repo with blog screenshots of the last 22 years 😅
Thankfully Alex did some pioneering work on this already and wrote two articles which will become handy:
In this article Max explains how to build a highlighter marker effect using only CSS.
The result is a nice looking effect to spice up the default highlighting style of the <mark> element.
This is the resulting CSS code from the article (now integrated in the blog here):
mark { margin: 0 -0.4em; padding: 0.1em 0.4em; border-radius: 0.8em 0.3em; background: transparent; background-image: linear-gradient( to right, rgba(255, 225, 0, 0.1), rgba(255, 225, 0, 0.7) 4%, rgba(255, 225, 0, 0.3) ); -webkit-box-decoration-break: clone; box-decoration-break: clone; }
Two nice CSS tricks from Alex:
ComCom orders: Swisscom must operate zero-settlement peering with Init7
This will cause implications in the industry at home and abroad. The proceedings revealed that Swisscom together with Deutsche Telekom had formed a cartel in order to force payments from content providers. Internet providers have a technical monopoly on access to their end customers and Swisscom acted as a kind of gatekeeper; only those who paid “enough” could send traffic (e.g. video streaming) to their end customers [...].
Commercial tea bags release millions of microplastics when in use.
A UAB research has characterised in detail how polymer-based commercial tea bags release millions of nanoplastics and microplastics when infused. The study shows for the first time the capacity of these particles to be absorbed by human intestinal cells, and are thus able to reach the bloodstream and spread throughout the body.
(via)
In the Pseudoscripting with <noscript> article, James McKee explains a nice trick for writing CSS that detects when Javascript is disabled.
It combines the <noscript> element with a Container Style Query, to provide clearly defined CSS classes that are active/inactive whenever Javascript is enabled/disabled.
I took this as inspiration to make some recently added Javascript-only pages on the blog degrade a bit more gracefully for non-Javascript users.
In the case of the On this day page and the Search page, there is now a message shown explaining that this functionality requires Javascript.
This is done simply with the <noscript> element and works well.
Additionally I used a trick similar to the one from the article to hide the Javascript-only content with CSS on these pages (eg. the search form).
This is achieved with the following CSS class definition which hides elements when Javascript is not enabled.
<noscript> <style> .js-only { display: none !important; } </style> </noscript>
With this in place, I can now mark all Javascript-only elements with the js-only class.
They are then hidden when someone uses the page with Javascript disabled, and visible for everyone else.
(via)
The Most Popular Recipes of 2024 from New York Times Cooking.
We’ve published over 1,000 delicious recipes this year. Here are your favorites: microwave chocolate pudding cake, one-pot chicken and rice, peanut butter noodles, taverna salad and more.
(via)
While integrating Opengist to serve code snippets in the blog, I discovered that everytime a snippet is loaded a _csrf cookie is set by Opengist.
This is not very cool, and I've found a way to prevent this using nginx.
Why is this _csrf cookie not cool on embedded code snippets?
How did I prevent the _csrf cookie with nginx?
I'm using the following (simplified) nginx reverse proxy config in front of the Opengist docker container.
It has a conditional if section where the headers-more-nginx-module is used to remove the Set-Cookie HTTP header, on the responses for the embedded code snippets.
The if condition is specific to my username and will need to be adjusted to your setup of course.
server { server_name gist.x-way.org; location / { if ( $uri ~* ^/x-way/[0-9a-fA-F]+\.js$ ) { more_clear_headers "Set-Cookie"; } proxy_pass http://127.0.0.1:6157; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; } }
This is a quite ugly hack.
I submitted a pull-request for Opengist to exclude the embedded code snippets from the CSRF middleware.
Let's see where this leads 🤞
Decided to self-host the handful of code snippets I embedded into the blogposts over time.
This will be one less dependency on an external service (GitHub Gist) for running this site :-)
I choose Opengist for hosting my code snippets.
Although I already run a GitBucket instance, I decided not to use it for hosting the code snippets of the blog.
This because in the past I had some performance issues and crashes that were triggered by Bots overloading the Docker container.
The installation of Opengist went very smooth.
It does not come with many dependencies and brings it's own SQLite database file (which should be more than enough for the code snippets in the blog).
I was positively surprised by the MFA and seamless Passkey integration it provides out of the box.
Also can it be configured to allow embedding/sharing of snippets for everyone while restricting the listing and editing to logged in users only.
And as an additional security benefit it helps to reduce the complexity of my CSP policy 🔐
If you're curious to see how the code snippets are rendered, have a look at the blogposts here or here.
- Separate subject from body with a blank line
- Limit the subject line to 50 characters (I often break this when there’s no message body)
- Capitalize the subject line
- Do not end the subject line with a period
- Use the imperative mood in the subject line
- Wrap the body at 72 characters
- Use the body to explain what and why vs. how
(via)
oxipng is a lossless PNG compression optimizer written in Rust.
On an initial test it seems to perform better than pngcrush.
(via)
I added a client-side search functionality to this static blog.
Similar to what is explained in this article by Stephan Miller, I added a search functionality to the blog.
The challenge was to do this while keeping the blog a static generated site.
Thus the choice to do all of the search client-side in JavaScript.
The way my current implementation works, is that there is a JSON blob with all the posts ever written in this blog.
This is loaded to the browser and indexed using Lunr.js.
The resulting search index is then used to provide the search functionality.
It comes with some convenient built-in search modifiers such as +, - and *.
To avoid reloading the whole JSON blob for each follow-up query on the search page, it intercepts the default form submit action and handles the search client-side.
Thus re-using the computed search index and saving the additional roundtrips accross the network.
The Earworm Eraser is a 40-second audio track designed specifically to squash earworms — a song on repeat circling around and around in your brain that can't easily be shaken off.
(via)
Recreated this screenshot from 21 years ago (first Mac) on my new Mac.
How does 2003 and 2024 compare?
Nowadays I'm using the regular Apple Mail.
X11 forwarding still works but is not really used.
Some Linux host is still around.
Mac remains the main device though.
Interestingly Linux still is a Intel device, whereas the Mac one is (again) running on a non-Intel CPU.
How to access my old encrypted files even though EncFS is no longer supported in Homebrew for macOS.
brew install gromgit/fuse/encfs-mac
==> Fetching dependencies for gromgit/fuse/encfs-mac: openssl@1.1 Error: openssl@1.1 has been disabled because it is not supported upstream! It was disabled on 2024-10-24.
How to install the (no longer supported) openssl@1.1 formula.
brew tap --force homebrew/core
brew edit openssl@1.1Comment out line 29, so it looks like:
#disable! date: "2024-10-24", because: :unsupported
HOMEBREW_NO_INSTALL_FROM_API=1 brew install openssl@1.1
Now we can install EncFS successfully.
brew install gromgit/fuse/encfs-mac ==> Fetching gromgit/fuse/encfs-mac ==> Downloading https://github.com/gromgit/homebrew-fuse/releases/download/encfs-mac-1.9.5/encfs-mac-1.9.5.arm64_monterey.bottle.tar.gz ==> Downloading from https://objects.githubusercontent.com/github-production-release-asset-[...] ==> Installing encfs-mac from gromgit/fuse ==> Pouring encfs-mac-1.9.5.arm64_monterey.bottle.tar.gz ==> Downloading https://formulae.brew.sh/api/cask.jws.json 🍺 /opt/homebrew/Cellar/encfs-mac/1.9.5: 65 files, 2.2MB ==> Running `brew cleanup encfs-mac`...
If desired, we can now run brew untap homebrew/core to cleanup the local copy of the formula repository.
Next step is to enable the (earlier installed) MacFuse kernel extension.
On macOS Sequoia this is a quite complicated process (needs disabling of multiple security features and some reboots).
Luckily the people from the MacFuse project have compiled a nice illustrated guide.
After this process is completed, we can finally decrypt the EncFS files.
encfs -v -f ./encrypted-folder ./mountpoint
The unencrypted files are available at ./mountpoint.
In my case I copied them to another folder as I no longer intend to use EncFS.
With the job done, I removed again all the EncFS software and re-enabled the security features of macOS.
brew uninstall encfs-mac brew uninstall openssl@1.1 brew uninstall macfuse
Then reboot into the Recovery environment and in the Startup Security Utility set the Security Policy again to Full Security. 🔐
A big part of the time used to move from my 2017 Intel MacBook Pro to my new 2024 M4 MacBook Pro was spent on migrating my Homebrew installation.
There are three aspects to the migration.
The impact of the change in CPU architecture was mostly taken care of by enabling the Rosetta 2 emulator to run Intel-binaries on the M4.
This immediately fixed the problem of my Terminal windows auto-closing on startup (as they now no longer failed to run the zsh Intel-binary).
But it did not solve all problems, particularly annoying was that vim could not be started and always failed with the following error:
dyld[31382]: Library not loaded: /System/Library/Perl/5.30/darwin-thread-multi-2level/CORE/libperl.dylib Referenced from: <77AC96DE-0453-3E1C-B442-EFE624110BAE> /usr/local/Cellar/vim/9.1.0750_1/bin/vim Reason: tried: '/System/Library/Perl/5.30/darwin-thread-multi-2level/CORE/libperl.dylib' (no such file), '/System/Volumes/Preboot/Cryptexes/OS/System/Library/Perl/5.30/darwin-thread-multi-2level/CORE/libperl.dylib' (no such file), '/System/Library/Perl/5.30/darwin-thread-multi-2level/CORE/libperl.dylib' (no such file, not in dyld cache), '/usr/local/lib/libperl.dylib' (no such file), '/usr/lib/libperl.dylib' (no such file, not in dyld cache)
My workaround for this was to use the default vim that comes bundled with macOS, by typing /usr/bin/vim.
Although it complained about some unsupported parts in my .vimrc, it at least started up and was usable enough to edit files.
The error itself seems due to some Perl system libraries that vim was compiled with and which now no longer exist in the new macOS version.
This is a typical problem which can be solved by re-installing Homebrew.
Re-installing Homebrew
The steps below follow this FAQ entry and are extended with what was needed to make it work for my situation.
Your mileage might vary!
arch -x86_64 /usr/local/bin/brew bundle dump --global
export PATH=/bin:/usr/bin:/sbin:/usr/sbin:$PATH
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
==> Next steps:
- Run these commands in your terminal to add Homebrew to your PATH:
echo >> /Users/aj/.zprofile
echo 'eval "$(/opt/homebrew/bin/brew shellenv)"' >> /Users/aj/.zprofile
eval "$(/opt/homebrew/bin/brew shellenv)"/opt/homebrew/bin/brew bundle install --global
Homebrew Bundle failed! 30 Brewfile dependencies failed to install.Homebrew Bundle failed! 30 Brewfile dependencies failed to install.
Outdated Xcode and missing Xcode command-line utilities
Due to the change in macOS version, the Xcode installation was outdated and also no usable command-line utilities were available.
This usually manifests in errors like these:
Installing ssh-audit ==> Fetching ssh-audit ==> Downloading https://raw.githubusercontent.com/Homebrew/homebrew-core/723e7ef695e15c790aab727c1da11a2a4610ad53/Formula/s/ssh-audit.rb ==> Cloning https://github.com/jtesta/ssh-audit.git Cloning into '/Users/aj/Library/Caches/Homebrew/ssh-audit--git'... ==> Checking out branch master Already on 'master' Your branch is up to date with 'origin/master'. Error: Your Xcode (15.1) at /Applications/Xcode.app is too outdated. Please update to Xcode 16.0 (or delete it). Xcode can be updated from the App Store. Error: Your Command Line Tools are too outdated. Update them from Software Update in System Settings. If that doesn't show you any updates, run: sudo rm -rf /Library/Developer/CommandLineTools sudo xcode-select --install Alternatively, manually download them from: https://developer.apple.com/download/all/. You should download the Command Line Tools for Xcode 16.0. Installing ssh-audit has failed!
Installing tdsmith/ham/direwolf ==> Fetching dependencies for tdsmith/ham/direwolf: portaudio ==> Fetching portaudio ==> Downloading https://ghcr.io/v2/homebrew/core/portaudio/manifests/19.7.0-1 ==> Downloading https://ghcr.io/v2/homebrew/core/portaudio/blobs/sha256:8ad9f1c15a4bc9c05a9dd184b53b8f5f5d13a2458a70535bfb01e54ce4f8b4bd ==> Fetching tdsmith/ham/direwolf ==> Downloading https://github.com/wb2osz/direwolf/archive/1.4-dev-E.tar.gz ==> Downloading from https://codeload.github.com/wb2osz/direwolf/tar.gz/refs/tags/1.4-dev-E ==> Installing direwolf from tdsmith/ham Error: Your Xcode (15.1) at /Applications/Xcode.app is too outdated. Please update to Xcode 16.0 (or delete it). Xcode can be updated from the App Store. Error: Your Command Line Tools are too outdated. Update them from Software Update in System Settings. If that doesn't show you any updates, run: sudo rm -rf /Library/Developer/CommandLineTools sudo xcode-select --install Alternatively, manually download them from: https://developer.apple.com/download/all/. You should download the Command Line Tools for Xcode 16.0. Installing tdsmith/ham/direwolf has failed!
This can be fixed in two steps.
First update Xcode via the App Store.
Then run the mentioned commands to install/update the command-line utilities:
sudo rm -rf /Library/Developer/CommandLineTools sudo xcode-select --install
With the latest Xcode and command-line utilities in place, trigger a new installation attempt for the affected applications:
brew install ssh-audit brew install tdsmith/ham/direwolf
Missing Rosetta 2 Intel emulation
Some of the Casks distributed by Homebrew are currently only available as Intel-binaries.
This usually manifests in warnings like these:
Installing gqrx ==> Caveats gqrx is built for Intel macOS and so requires Rosetta 2 to be installed. You can install Rosetta 2 with: softwareupdate --install-rosetta --agree-to-license Note that it is very difficult to remove Rosetta 2 once it is installed. ==> Downloading https://raw.githubusercontent.com/Homebrew/homebrew-cask/1ef784f287cce93f2bb54bea66ae7ac0953f623b/Casks/g/gqrx.rb ==> Downloading https://github.com/gqrx-sdr/gqrx/releases/download/v2.17.5/Gqrx-2.17.5.dmg ==> Downloading from https://objects.githubusercontent.com/github-production-release-asset-[...] ==> Installing Cask gqrx Error: It seems there is already an App at '/Applications/Gqrx.app'. ==> Purging files for version 2.17.5 of Cask gqrx Installing gqrx has failed!
Installing jitsi ==> Caveats jitsi is built for Intel macOS and so requires Rosetta 2 to be installed. You can install Rosetta 2 with: softwareupdate --install-rosetta --agree-to-license Note that it is very difficult to remove Rosetta 2 once it is installed. ==> Downloading https://github.com/jitsi/jitsi/releases/download/Jitsi-2.10/jitsi-2.10.5550.dmg ==> Downloading from https://objects.githubusercontent.com/github-production-release-asset-[...] ==> Installing Cask jitsi Error: It seems there is already an App at '/Applications/Jitsi.app'. ==> Purging files for version 2.10.5550 of Cask jitsi Installing jitsi has failed!
Installing keepassx Password: ==> Caveats keepassx is built for Intel macOS and so requires Rosetta 2 to be installed. You can install Rosetta 2 with: softwareupdate --install-rosetta --agree-to-license Note that it is very difficult to remove Rosetta 2 once it is installed. ==> Downloading https://raw.githubusercontent.com/Homebrew/homebrew-cask/1ef784f287cce93f2bb54bea66ae7ac0953f623b/Casks/k/keepassx.rb ==> Downloading https://www.keepassx.org/releases/2.0.3/KeePassX-2.0.3.dmg ==> Installing Cask keepassx ==> Changing ownership of paths required by keepassx with sudo; the password may be necessary. Error: It seems there is already an App at '/Applications/KeePassX.app'. ==> Purging files for version 2.0.3 of Cask keepassx Installing keepassx has failed!
Installing sequel-pro Warning: sequel-pro has been deprecated because it is discontinued upstream! It will be disabled on 2024-12-17. ==> Caveats sequel-pro has been deprecated in favor of Sequel Ace. brew install --cask sequel-ace sequel-pro is built for Intel macOS and so requires Rosetta 2 to be installed. You can install Rosetta 2 with: softwareupdate --install-rosetta --agree-to-license Note that it is very difficult to remove Rosetta 2 once it is installed. ==> Downloading https://github.com/sequelpro/sequelpro/releases/download/release-1.1.2/sequel-pro-1.1.2.dmg ==> Downloading from https://objects.githubusercontent.com/github-production-release-asset-[...] ==> Installing Cask sequel-pro Error: It seems there is already an App at '/Applications/Sequel Pro.app'. ==> Purging files for version 1.1.2 of Cask sequel-pro Installing sequel-pro has failed!
This can be fixed by running the mentioned command:
softwareupdate --install-rosetta --agree-to-license
With this in place, Intel-binaries will not be a problem anymore.
But as you can see there was actually a second failure in all these errors, which we are going to address next.
Old applications linger around in /Applications and block updates/re-installation
Homebrew nicely installed all the opensource applications into the new /opt/homebrew, but for the Casks which are distributed as binary application bundles and live in /Applications we end up with conflicts (as the new Homebrew installation does not know about the previously installed application bundles there).
This typically manifests in errors like these (also seen in the ones from the Rosetta section):
Installing 0-ad ==> Downloading https://releases.wildfiregames.com/0ad-0.0.26-alpha-osx-aarch64.dmg ==> Installing Cask 0-ad Error: It seems there is already an App at '/Applications/0 A.D..app'. ==> Purging files for version 0.0.26-alpha of Cask 0-ad Installing 0-ad has failed!
Installing brave-browser ==> Downloading https://updates-cdn.bravesoftware.com/sparkle/Brave-Browser/stable-arm64/173.91/Brave-Browser-arm64.dmg ==> Installing Cask brave-browser Error: It seems there is already an App at '/Applications/Brave Browser.app'. ==> Purging files for version 1.73.91.0 of Cask brave-browser Installing brave-browser has failed!
Installing burp-suite ==> Downloading https://portswigger-cdn.net/burp/releases/download?product=community&version=2024.10.3&type=MacOsArm64 ==> Installing Cask burp-suite Error: It seems there is already an App at '/Applications/Burp Suite Community Edition.app'. ==> Purging files for version 2024.10.3 of Cask burp-suite Installing burp-suite has failed!
Installing docker ==> Downloading https://raw.githubusercontent.com/Homebrew/homebrew-cask/1ef784f287cce93f2bb54bea66ae7ac0953f623b/Casks/d/docker.rb ==> Downloading https://desktop.docker.com/mac/main/arm64/175267/Docker.dmg ==> Installing Cask docker Error: It seems there is already an App at '/Applications/Docker.app'. ==> Purging files for version 4.36.0,175267 of Cask docker Installing docker has failed!
Installing gitup ==> Downloading https://github.com/git-up/GitUp/releases/download/v1.4.2/GitUp.zip ==> Downloading from https://objects.githubusercontent.com/github-production-release-asset-[...] ==> Installing Cask gitup Error: It seems there is already an App at '/Applications/GitUp.app'. ==> Purging files for version 1.4.2 of Cask gitup Installing gitup has failed!
Installing keeweb Password: ==> Downloading https://raw.githubusercontent.com/Homebrew/homebrew-cask/1ef784f287cce93f2bb54bea66ae7ac0953f623b/Casks/k/keeweb.rb ==> Downloading https://github.com/keeweb/keeweb/releases/download/v1.18.7/KeeWeb-1.18.7.mac.arm64.dmg ==> Downloading from https://objects.githubusercontent.com/github-production-release-asset-[...] ==> Installing Cask keeweb ==> Changing ownership of paths required by keeweb with sudo; the password may be necessary. chown: /Applications/KeeWeb.app/Contents/CodeResources: Operation not permitted [...] chown: /Applications/KeeWeb.app: Operation not permitted Error: It seems there is already an App at '/Applications/KeeWeb.app'. ==> Purging files for version 1.18.7 of Cask keeweb Installing keeweb has failed!
Installing netnewswire ==> Downloading https://github.com/Ranchero-Software/NetNewsWire/releases/download/mac-6.1.4/NetNewsWire6.1.4.zip ==> Downloading from https://objects.githubusercontent.com/github-production-release-asset-[...] ==> Installing Cask netnewswire Error: It seems there is already an App at '/Applications/NetNewsWire.app'. ==> Purging files for version 6.1.4 of Cask netnewswire Installing netnewswire has failed!
Installing obs ==> Downloading https://raw.githubusercontent.com/Homebrew/homebrew-cask/1ef784f287cce93f2bb54bea66ae7ac0953f623b/Casks/o/obs.rb ==> Downloading https://cdn-fastly.obsproject.com/downloads/OBS-Studio-30.2.3-macOS-Apple.dmg ==> Installing Cask obs Error: It seems there is already an App at '/Applications/OBS.app'. ==> Purging files for version 30.2.3 of Cask obs Installing obs has failed!
Installing transmission ==> Downloading https://github.com/transmission/transmission/releases/download/4.0.6/Transmission-4.0.6.dmg ==> Downloading from https://objects.githubusercontent.com/github-production-release-asset-[...] ==> Installing Cask transmission Error: It seems there is already an App at '/Applications/Transmission.app'. ==> Purging files for version 4.0.6 of Cask transmission Installing transmission has failed!
Installing tunnelblick Password: ==> Caveats For security reasons, tunnelblick must be installed to /Applications, and will request to be moved at launch. ==> Downloading https://raw.githubusercontent.com/Homebrew/homebrew-cask/1ef784f287cce93f2bb54bea66ae7ac0953f623b/Casks/t/tunnelblick.rb ==> Downloading https://github.com/Tunnelblick/Tunnelblick/releases/download/v4.0.1/Tunnelblick_4.0.1_build_5971.dmg ==> Downloading from https://objects.githubusercontent.com/github-production-release-asset-[...] ==> Installing Cask tunnelblick ==> Changing ownership of paths required by tunnelblick with sudo; the password may be necessary. chown: /Applications/Tunnelblick.app/Contents/CodeResources: Operation not permitted [...] chown: /Applications/Tunnelblick.app: Operation not permitted Error: It seems there is already an App at '/Applications/Tunnelblick.app'. ==> Purging files for version 4.0.1,5971 of Cask tunnelblick Installing tunnelblick has failed!
Installing vlc ==> Downloading https://raw.githubusercontent.com/Homebrew/homebrew-cask/1ef784f287cce93f2bb54bea66ae7ac0953f623b/Casks/v/vlc.rb ==> Downloading https://get.videolan.org/vlc/3.0.21/macosx/vlc-3.0.21-arm64.dmg ==> Downloading from http://mirror.easyname.ch/videolan/vlc/3.0.21/macosx/vlc-3.0.21-arm64.dmg ==> Installing Cask vlc Error: It seems there is already an App at '/Applications/VLC.app'. ==> Purging files for version 3.0.21 of Cask vlc Installing vlc has failed!
Installing wireshark Password: ==> Downloading https://2.na.dl.wireshark.org/osx/all-versions/Wireshark%204.4.2%20Arm%2064.dmg ==> Installing Cask wireshark ==> Running installer for wireshark with sudo; the password may be necessary. installer: Package name is ChmodBPF installer: Installing at base path / installer: The install was successful. ==> Running installer for wireshark with sudo; the password may be necessary. Error: It seems there is already an App at '/Applications/Wireshark.app'. installer: Package name is Add Wireshark to the system PATH installer: Installing at base path / installer: The install was successful. ==> Purging files for version 4.4.2 of Cask wireshark Installing wireshark has failed!
Now that we have the full list, here is how I fixed these errors:
brew install --cask 0-ad brew install --cask brave-browser ...
With this, most of the fixing is concluded.
Thus let's go to the warnings and errors that I consciously ignore.
Warnings and errors to ignore
Some of the warnings and errors I consciously ignore.
A lot of them come from no longer maintained/available software which Homebrew no longer provides, or which have become obsolete as another software does the same job now.
Also in some cases it is just that I no longer use the software and thus do not need to spend the time to fix their installation problems.
Of course there are some errors in software which I still want to use and which I have not managed to fix yet, we will get to them later.
Here now the warnings and errors which I choose to ignore:
Tapping homebrew/cask Error: Tapping homebrew/cask is no longer typically necessary. Add --force if you are sure you need it for contributing to Homebrew. Tapping homebrew/cask has failed!
Tapping homebrew/core Error: Tapping homebrew/core is no longer typically necessary. Add --force if you are sure you need it for contributing to Homebrew. Tapping homebrew/core has failed!
Skipping gdb (no bottle for Apple Silicon)
Installing hping Error: hping has been disabled because it is not maintained upstream! It was disabled on 2024-02-15. Installing hping has failed!
Skipping hyperkit (no bottle for Apple Silicon)
Installing xhyve Warning: 'xhyve' formula is unreadable: No available formula with the name "xhyve". Warning: No available formula with the name "xhyve". Error: No formulae found for xhyve. ==> Searching for similarly named formulae... Installing xhyve has failed!
Installing jsmin Warning: 'jsmin' formula is unreadable: No available formula with the name "jsmin". Did you mean jsmn, jasmin or jsign? Warning: No available formula with the name "jsmin". Did you mean jsmn, jasmin or jsign? ==> Searching for similarly named formulae... ==> Formulae jsmn jasmin jsign To install jsmn, run: brew install jsmn Installing jsmin has failed!
Installing sslyze Error: sslyze has been disabled because it uses deprecated `openssl@1.1`! It was disabled on 2024-04-05. Installing sslyze has failed!
Installing virtualbox-extension-pack Warning: Cask 'virtualbox-extension-pack' is unavailable: No Cask with this name exists. ==> Searching for similarly named casks... ==> Casks virtualbox@beta To install virtualbox@beta, run: brew install --cask virtualbox@beta Installing virtualbox-extension-pack has failed!
Installing docker-compose-completion Warning: 'docker-compose-completion' formula is unreadable: No available formula with the name "docker-compose-completion". Did you mean docker-completion? Warning: No available formula with the name "docker-compose-completion". Did you mean docker-completion? ==> Searching for similarly named formulae... ==> Formulae docker-completion To install docker-completion, run: brew install docker-completion Installing docker-compose-completion has failed!
Installing visitors Error: visitors has been disabled because it has a removed upstream repository! It was disabled on 2024-02-21. Installing visitors has failed!
Installing osxfuse Password: ==> Caveats `osxfuse` has been succeeded by `macfuse` as of version 4.0.0. To update to a newer version, do: brew uninstall osxfuse brew install macfuse osxfuse requires a kernel extension to work. If the installation fails, retry after you enable it in: System Settings → Privacy & Security For more information, refer to vendor documentation or this Apple Technical Note: https://developer.apple.com/library/content/technotes/tn2459/_index.html You must reboot for the installation of osxfuse to take effect. ==> Downloading https://raw.githubusercontent.com/Homebrew/homebrew-cask/1ef784f287cce93f2bb54bea66ae7ac0953f623b/Casks/o/osxfuse.rb ==> Downloading https://github.com/osxfuse/osxfuse/releases/download/osxfuse-3.11.2/osxfuse-3.11.2.dmg ==> Downloading from https://objects.githubusercontent.com/github-production-release-asset-[...] ==> Installing Cask osxfuse ==> Running installer for osxfuse with sudo; the password may be necessary. installer: Error - Das FUSE for macOS Installationspacket ist nicht kompatibel mit dieser macOS Version. Error: Failure while executing; `/usr/bin/sudo -u root -E LOGNAME=aj USER=aj USERNAME=aj -- /usr/sbin/installer -pkg /opt/homebrew/Caskroom/osxfuse/3.11.2/Extras/FUSE\ for\ macOS\ 3.11.2.pkg -target /` exited with 1. Here's the output: installer: Error - Das FUSE for macOS Installationspacket ist nicht kompatibel mit dieser macOS Version. ==> Purging files for version 3.11.2 of Cask osxfuse Installing osxfuse has failed!
Installing tuntap Warning: Cask 'tuntap' is unavailable: No Cask with this name exists. ==> Searching for similarly named casks... ==> Casks tunetag To install tunetag, run: brew install --cask tunetag Installing tuntap has failed!
Installing mailtrackerblocker Warning: mailtrackerblocker has been deprecated because it is now exclusively distributed on the Mac App Store! It will be disabled on 2025-04-22. ==> Downloading https://raw.githubusercontent.com/Homebrew/homebrew-cask/1ef784f287cce93f2bb54bea66ae7ac0953f623b/Casks/m/mailtrackerblocker.rb Error: This cask does not run on macOS versions newer than Ventura. Installing mailtrackerblocker has failed!
This concludes the warnings and errors I ignored.
And there is a little exception.
For mailtrackerblocker I did not completely ignore the error, but rather installed the paid MailTrackerBlocker for Mail application from the App Store.
Cleaning up the old Homebrew installation
We still have all the no longer needed Intel-binaries and old Homebrew framework in /usr/local.
Time to clean this up.
Homebrew nicely provides a script to help (partially) with this:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/uninstall.sh)" -- --path=/usr/local
This will remove most of the old Homebrew installation but will likely fail to remove everything.
Especially in my situation with years of cruft accumulated, this was the case.
I ended up with the following output from the cleanup script:
==> /usr/bin/sudo rmdir /usr/local rmdir: /usr/local: Operation not permitted Warning: Failed during: /usr/bin/sudo rmdir /usr/local Warning: Homebrew partially uninstalled (but there were steps that failed)! To finish uninstalling rerun this script with `sudo`. The following possible Homebrew files were not deleted: /usr/local/.com.apple.installer.keep /usr/local/Cellar/ /usr/local/Frameworks/ /usr/local/Homebrew/ /usr/local/MacGPG2/ /usr/local/bin/ /usr/local/etc/ /usr/local/include/ /usr/local/lib/ /usr/local/man/ /usr/local/opt/ /usr/local/remotedesktop/ /usr/local/sbin/ /usr/local/share/ /usr/local/tests/ /usr/local/var/ You may wish to remove them yourself.
I manually went through all these folders and removed what I could identify as obsolete and no longer needed leftovers.
Important though for example the MacGPG2 folder seems to come from the GPGTools installation, thus be aware that there are other things than Homebrew which might have installed some software under /usr/local and not everyhting must necessarily be removed.
Unsolved problems
As mentioned there are some things which I haven't figured out how to fix yet.
I'm missing a good solution for encfs (which is no longer provided by Homebrew due to license changes of the underlying MacFuse project).
Compiling from source (at least through Homebrew) is not supported either (as it is marked as Linux-only and complilation is not supported anymore on macOS).
Update: found a solution for how to install EncFS on macOS Sequoia.
Another missing thing (which is more a problem of not having time to deal with it yet), is the Perl ecosystem including CPAN package management. Here probably some research to find the canonical way for installing Perl in macOS 15 is all I need. 🐪
After switching to an Apple Silicon CPU, I'm now hunting down all the Intel-only binaries on my system.
Using the Activity Monitor and ordering the processes by Kind is quite helpful for this.
So I identified Syncthing to be still running as an Intel-only binary with the Rosetta 2 emulation.
My installation of Syncthing is quite old, so it isn't managed by Homebrew yet.
This actually made the switch quite easy:
rm $HOME/bin/syncthing rm $HOME/bin/syncthing.old
The new laptop arrived and now it's time for the big migration.
This includes not only a change in the physical device, but also a change in OS version and more importantly in CPU architecture.
Luckily there are some very helpful tools making this a quite smooth experience.
Overal plan of attack:
This plan worked quite well for me (as I'm already writing this blogpost with the new laptop).
There are of course some expected and some unexptected problems that need to be addressed.
Rosetta 2
Directly after the first start, there was a system message asking me if Rosetta 2 should be enabled.
Rosetta 2 is the emulation layer built into macOS that allows to run Intel-only binaries on the Apple Silicon CPUs.
To reduce the ammount of immediate problems to fix, I enabled it for now.
Even though over time I plan to replace all Intel-only binaries with newer versions.
1Password
One unexpected problem was 1Password.
There I was prompted to install the old version 7 from the App Store.
It took some time to figure out that the current version 8 is no longer distributed through the App Store.
Instead I had to remove the (freshly installed) 1Password 7 App from /Applications.
And then needed to download their custom installer from their website.
The installer in turn then did download and install the latest 1Password version 8.
Homebrew
On the list of expected problems was Homebrew.
Here not only I had a big collection of pre-compiled (for Intel) opensource binaries that needed to be changed into pre-compiled binaries for Apple Silicon.
But also the root folder of the whole Homebrew installation changed from /usr/local to /opt/homebrew.
And to make matters worse, some of the non-opensource software distributed by Homebrew in so called casks keeps using the old /usr/local.
For the migration of the binaries, I followed the FAQ entry here.
As expected this did not go over completely smooth and quite some research, manual fixing and cleanup was needed.
I will write more about the problems/fixes and tricks I found out in a future blogpost.
Update: please have a look at the dedicated blogpost for all the tricks and learnings of the Homebrew migration.
GPGTools
Not completely unexpected, but surprisingly smooth was the migration of MacGPG and the GPG plugin for Mail.app.
They provide a dedicated version of the software which brings compatibility with macOS Sequoia.
After running the installer to update the software, only a re-entering of the license key is needed and everything works as before.
Besides the already mentioned surprises with Homebrew, there are still some other issues left to be fixed (and possibly new ones to be discovered).
Overall the laptop is working very well and my familiar environment is mostly there 😌

It's getting closer and closer... 😊
My current laptop is dying of age after 7 years. Thus I'm getting a new one to replace it.
As part of the research, I looked for my last laptop purchase.
I not only found my last one, but also all the previous ones.
So I established my personal Mac history:
| Purchased | Type | Display | Processor | Memory | Storage |
|---|---|---|---|---|---|
| October 2003 | PowerBook | 15.2″ | 1.25GHz PowerPC G4 | 512MB | 80GB |
| January 2007 | MacBook Pro | 15.4″ | 2.33GHz Intel Core 2 Duo | 2GB | 120GB |
| May 2012 | MacBook Pro | 15.4″ | 2.5GHz Quad-Core Intel Core i7 | 8GB | 750GB |
| October 2017 | MacBook Pro | 13.3″ | 2.3GHz Dual-Core Intel Core i5 | 16GB | 1TB |
| November 2024 | MacBook Pro | 14.2″ | M4 Pro 14-Core CPU, 20-Core GPU, 16-Core Neural Engine | 48GB | 2TB |
Reflecting on it, it seems I get quite a good milage out of my laptops.
Current replacement due to age related failures after 7 years is the top one.
The previous 2017 replacement was similar due to age related failures after 5 years.
For the 2012 replacement it is a bit of a different story, as my laptop at the time was stolen from me.
But I still got five years out of it before that.
The 2007 replacement was the switch to Intel after 4 years on PowerPC.
I was very happy with my PowerBook at the time, even helped to reverse-engineer the wireless chipset to write the Linux driver for it :-)
In the GitFlops: The Dangers of Terraform Automation Platforms article Elliot Ward highlights how Terraform automation platforms can be exploited to compromise cloud environments.
In particular it looks at how to exploit the terraform plan phase to execute commands and gain access to cloud infrastructure credentials.
In combination with a classic GitOps flow, where unprivileged users can open pull-requests and terraform plan is run on these pull-requests, this creates privilege escalation vulnerabilities putting the cloud infrastructure at risk.
In terms of preventing this, the recommendation is to validate Terraform config before running terraform plan on it.
One tool mentioned in the article that can be used to for this validation is Conftest.
A month ago, Elliot also presented the topic at the BSides Bern conference.
The slides of the presentation have been made available by the conference, here is a copy.
The Electronic Frontier Foundation provides the Surveillance Self-Defense guide.
When talking about security it is important to known what you want to protect.
The Your Security Plan module of the guide covers this topic and is a good starting point.
(via)
The static pages of the blog here are served from a lighttpd container with an nginx proxy in front.
I was looking through the lighttpd access logs and was a bit annoyed as it showed the internal IP of the nginx proxy.
My nginx instance is already setup to forward the actual remote IP in the X-Real-IP header.
Thus I needed to make lighttpd use the forwarded IP from the header in the access logs.
This can be achieved with the extforward module using the following configuration snippet:
server.modules += ("mod_extforward")
extforward.headers = ("X-Real-IP")
extforward.forwarder = ("10.111.0.0/16" => "trust")
With this config, lighttpd uses the X-Real-IP in the access logs.
The override is only performed when the connection comes from the 10.111.0.0/16 subnet.
Which prevents remote IP spoofing via injected/faked headers.
(the 10.111.0.0/16 subnet is my internal container network where nginx is running)
The other morning I was greeted by a mailbox full of messages from failed cronjobs.
The reported error message was:
<28>Nov 7 02:51:02 ntpleapfetch[3253838]: Download from https://www.ietf.org/timezones/data/leap-seconds.list failed after 6 attempts --2024-11-07 02:51:02-- https://www.ietf.org/timezones/data/leap-seconds.list Resolving www.ietf.org (www.ietf.org)... 2606:4700::6810:2d63, 2606:4700::6810:2c63, 104.16.45.99, ... Connecting to www.ietf.org (www.ietf.org)|2606:4700::6810:2d63|:443... connected. HTTP request sent, awaiting response... 404 Not Found 2024-11-07 02:51:02 ERROR 404: Not Found.
The failing cronjobs were weekly invocations of ntpleapfetch to get the latest list of leap seconds.
After some research I found out that indeed the URL returns a 404 and that there was no newer version of the Debian package available to try.
Also the bugtracker didn't show anyone else dealing with this problem.
Thus I started looking at the source code of ntpsec
(which provides the ntpleapsec script).
I found a commit with the promising title of Fix URL used by ntpleapfetch.
This commit corrects the URL used for downloading the leap seconds list in the script.
Later I also found a corresponding message in the ntpsec users mailing list.
For my Debian systems there is no updated package with the new URL available yet.
Thus I used the following one-liner to directly fix the ntpleapfetch script.
sed -i -e 's_^LEAPSRC="https://.*"_LEAPSRC="https://data.iana.org/time-zones/tzdb/leap-seconds.list"_' /usr/sbin/ntpleapfetch
In his writing secure Go code article, Jakub Jarosz lists tools that help with writing secure Go code.
The article lists the tools and for each of them explains what it does and how it contributes to writing secure Go code.
The following tools are covered:
go vetstaticcheckgolangci-lintgo test -racegovulncheckgosec
An interesting learning for me whas that govulncheck can not only be used to analyze source code, but also to analyze existing binaries.
And there it scans the used libraries for vulnerabilities and wether the vulnerable code paths are actually invoked by the code in the binary.
In the build pipelines of my Go programs, some of these tools are already used.
Room for improvement exists when it comes to using the govulncheck and gosec tools.
Another lonely winter weekend task :-)
Please publish and share more from Jeff Triplett. (via)
Friends, I encourage you to publish more, indirectly meaning you should write more and then share it.
You don’t have to change the world with every post. You might publish a quick thought or two that helps encourage someone else to try something new, listen to a new song, or binge-watch a new series.
Our posts are done when you say they are. You do not have to fret about sticking to landing and having a perfect conclusion. Your posts, like this post, are done after we stop writing.
Reminds me that I should setup some POSSE mechanism for the blog.
Maybe during one of the grey and cold weekends this winter :-)
I wanted to see the output of a program repeatedly with the watch command.
To my surprise this failed on my macOS laptop with the following error:
% watch ipaddr zsh: command not found: watch
Turns out that macOS does not have the watch command installed by default.
% which watch watch not found
Thankfully this can be fixed easily by using homebrew to install the watch binary:
% brew install watch
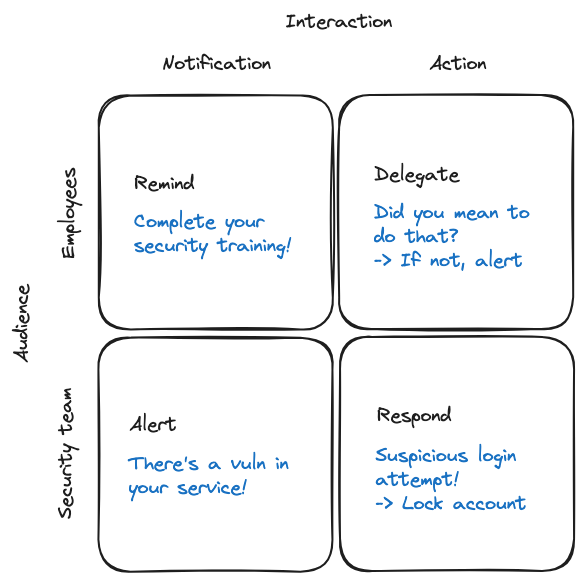
In the Delegating security remediation to employees via Slack article, Maya Kaczorowski coins the term SlackSecOps to describe automation and delegation of security tasks to employees.
The article gives a nice overview of some ideas that are more and more applied by security teams and tools.
A couple years ago such ideas were mostly custom built bots/automations at larger companies, but not shared more widely.
Nowadays there seems to be a much broader adoption of these in companies, especially the Alert and Remind categories.
The most interesting ones are Delegation and Respond, which I would claim also can have the most impact.
By delegating security remediation tasks directly to the involved persons, the handling of the task becomes more efficient as all the context is available.
And then by providing the automation to the delegee to directly perform the remediation in self-service, this critically shortens the response cycle.
With the shortened response cycle, the exposure window of a vulnerable configuration is minimized, which reduces the risk of exploitation.
Similar to the 512KB club, there exists the 250KB club.
It collects web pages that focus on performance, efficiency and accessibility.
Qualifying sites must fullfil one requirement.
The website must not exceed 256KB compressed size.
256KB Club also contains very niche sites and is great to discover some new corners of the Internet.
The linked pages are often minimalistic personal pages and geeky blogs.
I submitted my blog for inclusion in the club, as it measures less than 250KB.
It was accepted a day earlier than for the 512KB club :-)
Now the blog has its own page in the club: https://250kb.club/blog-x-way-org/
![]()
Some time ago I discovered the 512KB club.
It collects performance-focused websites from across the Internet.
Qualifying sites must fullfil two requirements to participate.
The site must provide a reasonable amount of content.
And the total uncompressed web resources must not exceed 512KB.
512KB Club is a nice resource to discover more niche sites on the Internet.
Often these are handcrafted personal sites and blogs with unique content.
They remind me of all the unique personal sites and blogs from before the web2.0/social-media/walled-garden time.
My blog is also very lightweight (currently clocking 39.48kB on the Cloudflare URL Scanner), thus I submitted it for inclusion in the list.
It was accepted recently and is now listed as part of the Green Team (sites smaller than 100KB).
![]()
Found this cute snippet in the Makefile of the NumWorks Epsilon codebase. It is a rudimentary implementation of the cowsay functionality.
We also see how it is used in the clena: cowsay_CLENA clean part.
I like how it reminds about the typo when calling the clena instead of the clean target.
It gives a clear but unintrusive message about the typo, and then also does what was intented (running the clean target).
.PHONY: cowsay_% cowsay_%: @echo " -------" @echo "| $(*F) |" @echo " -------" @echo " \\ ^__^" @echo " \\ (oo)\\_______" @echo " (__)\\ )\\/\\" @echo " ||----w |" @echo " || ||" .PHONY: clena clena: cowsay_CLENA clean
In the Realizing Meshtastic's Promise with the T-Deck article, Jeff Geerling showcases the experimental device-ui for the T-Deck.
This experimental UI looks already very pretty and I expect that it will provide a very nice Meshtastic experience once all features have been implemented.
The article also contains instructions on how to install a development version of the experimantal UI based on some CI snapshots.
Maybe something to try out one of these days :-)
In his Writing one sentence per line article, Derek Sivers explains the benefits of writing one sentence per line.
The approach leverages that whitespace in HTML source code is collapsed when being rendered in the browser.
Thus we can have a much more writer-friendly text formatting when editing the text, while still providing a nicely rendered output to whoever views the resulting page in a browser.
The main advantages outlined in the article are:
It helps you judge each sentence on its own.
It helps you vary sentence length.
It helps you move sentences.
It helps you see first and last words.
I really like this approach and will apply it in my future writing on the blog.
The indenting of text (not explicitly mentioned in the article but visible in the source) is also something I will try to adopt.
Here is how the above two paragraphs look in the source text:
<p> The main advantages outlined in the article are:<br> It helps you judge each sentence on its own.<br> It helps you vary sentence length.<br> It helps you move sentences.<br> It helps you see first and last words. </p> <p> I really like this approach and will apply it in my future writing on the blog.<br> The indenting of text (not explicitly mentioned in the article but visible in the source) is also something I will try to adopt. </p>
sshidentifierlogger is a small tool that I started writing about 5 years ago and have been using on some of my hosts.
Its purpose is to listen to network traffic and passively collect identification strings during SSH handshakes.
Initially I had a lot of fail2ban activity on my jumphost, blocking many SSH scanning/enumeration/bruteforcing attempts and wanted to know what software the attackers use.
A bit particular is that sshidentifierlogger does not depend on the classic C library libpcap, but rather uses the go-native pcapgo implementation by gopacket.
Thus it can be cross-compiled on any platform, which comes in handy when you do not want to install the full go buildchain on your jumphost.
The collected data is quite interesting (most of the scanning used to be done with libssh2).
Which I did leverage to write iptables rules blocking packets with undesired SSH identification strings.
This has been quite successfull in reducing the amount of fail2ban activity :-)
The Blockquotes and Pre-formatted text sections in the HTML for People book inspired me to improve the styling of the blog.
The following code now defines the visual appearance of blockquote and pre elements in the blog:
blockquote { border-left: 1px dotted #ffbb18; padding-left: 21px; margin-left: 21px; } pre { background-color: #f9f7f7; border-radius: 4px; padding: 4px; }
To see it in effect, scroll down to the Hidden Pref to Restore Slow Motion Dock Minimizing on MacOS or Notifying external services about changes in the blog posts.
Today I played around a bit with a Meshtastic device and tried to configure it through the Web Serial API in Chrome.
On my Linux system it could see the device but not really change any values, update firmware etc.
This confused me for some time, until I looked at the permissions of /dev/ttyACM0 (which were crw-rw----).
A quick sudo chmod a+rw /dev/ttyACM0 later, and I could write to the configuration of the Meshtastic device.
The more tedious part was that after every config change the device rebooted and the USB serial connection was re-initialized by Linux, thus I needed to re-run the chmod command after every change. Luckily I figured out how to enable WiFi on the device and from then on no longer needed the serial access.
Turns out that the procedure for enabling Visual Voicemail with Galaxus Mobile is the same as for TalkTalk.
In my case their database entry was somehow stuck and I first needed to send a VVM OFF to 935 before starting the procedure.
Daring Fireball describes how to restore the old trick of slow motion MacOS Dock effects:
In the midst of recording last week’s episode of The Talk Show with Nilay Patel, I offhandedly mentioned the age-old trick of holding down the Shift key while minimizing a window (clicking the yellow button) to see the genie effect in slow motion. Nilay was like “Wait, what? That’s not working for me...” and we moved on.
What I’d forgotten is that Apple had removed this as default behavior a few years ago (I think in MacOS 10.14 Mojave), but you can restore the feature with this hidden preference, typed in Terminal:
defaults write com.apple.dock slow-motion-allowed -bool YESThen restart the Dock:
killall DockOr, in a single command:
defaults write com.apple.dock slow-motion-allowed -bool YES; killall DockI had forgotten that this had become a hidden preference, and that I’d long ago enabled it.
For some time now, I'm notifying blo.gs about changes in the blog. After looking a bit into how search engines percieve my website recently, I learned that they also have some notification mechanisms for new pages/blogposts.
Thus I upgraded the oneliner into a dedicated script to notify external services about changes in the blog.
It is optimized for my Jekyll setup, where the generated pages in the _site folder are stored in git.
The notification ignores changes to summarized pages like rss.xml etc to only trigger notifications when there are changes in the original blog posts.
Here's the script, feel free to re-use (it expects to have MYDOMAIN, INDEXNOW_API_KEY and BING_API_KEY defined as environment variables):
#!/bin/bash set -e set -u set -o pipefail CHANGES="$(git diff --name-only HEAD HEAD~1 -- _site)" # early abort if no changes on _site if [ -z "$CHANGES" ] ; then echo "No changes in _site found" exit 0 fi # build URL list URLLIST="\"https://${MYDOMAIN}/\"" for f in $CHANGES ; do case "$f" in _site/robots.txt|_site/humans.txt|_site/about.html|_site/rss.xml|_site/atom.xml|_site/feed.json|_site/sitemap.xml) continue ;; *) url=$(echo "$f"|sed -e "sX^_siteXhttps://${MYDOMAIN}X") URLLIST="${URLLIST},\"${url}\"" ;; esac done if [ "\"https://${MYDOMAIN}/\"" = "$URLLIST" ] ; then echo "No relevant changes in _site found, skipping notifications" exit 0 fi # notify ping.blo.gs (Automattic) about updates curl --fail -s -D - -X POST http://ping.blo.gs -H 'content-type: text/xml' --data "<?xml version=\"1.0\"?><methodCall><methodName>weblogUpdates.extendedPing</methodName><params><param><value>x-log</value></param><param><value>https://${MYDOMAIN}/</value></param><param><value></value></param><param><value>https://${MYDOMAIN}/rss.xml</value></param></params></methodCall>" # report changed URLs to indexnow, include /indexnow canary URL curl --fail -s -D - -X POST https://api.indexnow.org/IndexNow -H 'content-type: application/json; charset=utf-8' --data "{\"host\":\"${MYDOMAIN}\",\"key\":\"${INDEXNOW_API_KEY}\",\"urlList\":[${URLLIST},\"https://${MYDOMAIN}/indexnow\"]}" # report changes URLs to bing, include /bingsubmit canary URL curl --fail -s -D - -X POST "https://ssl.bing.com/webmaster/api.svc/json/SubmitUrlbatch?apikey=${BING_API_KEY}" -H 'content-type: application/json; charset=utf-8' --data "{\"siteUrl\":\"https://${MYDOMAIN}\",\"urlList\":[${URLLIST},\"https://${MYDOMAIN}/bingsubmit\"]}"
When you switch to TalkTalk as your mobile phone provider, by default Visual Voicemail for your iPhone is not enabled.
And you're stuck with the 90s voiceprompt of the 'Talkbox'.
The following steps will activate Visual Voicemail for your iPhone:
VVM ON to the number 935.No festival this weekend. Did some hiking with friends instead.
Last weekend I attended the Subset Festival. It was the first edition of a new drum and bass focused festival.
There were some great artists there, most of them I knew before and was very much looking forward to see them live.
My favorite one was (unsurprisingly?) Andromedik, but also liked Hybrid Minds, Netsky and Andy C.
Very cool was that the festival was rather small, so felt quite intimate and super close to the artists.
Could post the same music video as two weeks ago (Andromedik's remix of The Feeling, which he said is a song very close to his heart), but you should also discover some other tracks.
Thus here we go with the recently released Paradise 🥳
Building up on the changes from the canonical hints, I simplified the structure of the archive links.
Now it's /year/month/ everywhere.
Which of course brings another round of redirects to support in the nginx config to map the /archive/archive-year-month.html links to /year/month/ 🙈
In theory all previous link schemes should still work, but if you find a broken link, please let me know :-)
To help regular search engines be less confused about the various pages of the blog (especially multiple generations of old inherited URL schemes), I added canonical hints to some pages.
Mostly straight-forward, except for the archives where I chose the concise /year/month/ scheme instead of the full /archive/archive-year-month.html.
Curious to see how this works out. Currently the links in the navigation and overview point to the full URLs, and the short ones are only implemented with rewrites in nginx and visible in the canonical hints.
I encountered an old Debian system and tried to upgrade it from Debian 10 (buster) to Debian 12 (bookworm).
During the apt-get dist-upgrade it did run into a problem, where libcrypt.so.1 was removed and the upgrade failed to continue.
Additionally this caused that dpkg itself also stopped working and that sshd stopped accepting new connections.
Thus fixing the following error became urgent:
/usr/bin/python3: error while loading shared libraries: libcrypt.so.1: cannot open shared object file: No such file or directory
Luckily I was not the first person to run into this issue.
In a Stack Overflow answer I found the crucial workaround taken from a comment on the corresponding Debian bugreport.
The following steps allow to manually install a copy of the missing libcrypt.so files to fix the issue (when running this you might have a newer version of the package at hand, thus adjust the dpkg-deb step accordingly):
cd /tmp apt -y download libcrypt1 dpkg-deb -x libcrypt1_1%3a4.4.33-2_amd64.deb . cp -av lib/x86_64-linux-gnu/* /lib/x86_64-linux-gnu/ apt -y --fix-broken install
Applied the CSS flexbox mechanism to the archive page.
This helps to transform the steadily growing lists of monthly archive links into a more userfriendly layout, going from a single column to eight columns and bringing all the links above 'the fold'.
I'm continueing my festival summer also this weekend. Yesterday I've attended the Simmentaler Bier Festival, which celebrates the 10 year anniversary of the Simmentaler Bier brewery.
The festivities included some fine music from far away and not so far away.
Rooftop Sailors opened the afternoon with their refreshing rock music.
Then came my favorite, Open Season, which was a nostalgy throwback as I was attending their concerts already 22 years ago ❤️
Last band of the day was Delinquent Habits, which brought their habit from LA to serve the public Tequila shots during the concert.
One of my favorite moments from the second weekend of ZÜRICH OPENAIR 2024: the concert of Lost Frequencies, especially the drum&bass live performance of The Feeling 🥳
Finally took the time to create a /now page and add it to the blog: /now 🎉
Still need to figure out if it will eventually replace the about page or not.
For now the about page links to the now page.
Proton Mail can sign (and encrypt) emails when it knows the PGP key of the correspondent. For this is provides PGP keys to its users.
Unfortunately most of them are not searchable via the traditional PGP keyservers. With the following command you can download the public PGP key of a Proton Mail user:
curl -s 'https://api.protonmail.ch/pks/lookup?op=get&search=user@protonmail.com'
Also, just discovered that GPG Keychain on Mac detects if the clipboard contains a PGP key and asks if it should import it. Very nice feature which saves a couple clicks :-)
Thanks to this post on Hacker News, I was reminded of the joy of regex crosswords :-)
Nice to see that the regexcrossword.com site has gained quite a list of puzzles and challenges since the last time I blogged about it.
Also very cool is the RegEx Crossword project of Jimb Esser, which provides a very smooth interface for solving hexagonal regex crosswords in the browser.
I remember solving the original MIT hexagonal regex crossword on paper back in the time.
And in addition there is a built-in editor which allows you to create your own hexagonal regex crosswords.
Thinking of using this to create some fun puzzle for the colleagues at work.
Vim Racer is a fun game to show off your vi skills 🚀
(also insightful to explore the leaderboard and see which commands were used by others)
Catchy memory from the first weekend of ZÜRICH OPENAIR 2024: Armin van Buuren's version of Artemas - I Like the Way You Kiss Me, which is very similar to the Bassjackers Remix 🔊
Added the /reading page to the blog to keep a list of various books I'm currently reading.
It is very bare-bones currently, I expect over time it will grow (both in number of books and also in amount of content, such as ratings, links and commentary).
Might take a while, stay tuned 🤓
Amazing discovery from the recent Paléo Festival: Lucie Antunes
Not seeing any emoji in Chrome on Linux?
The following fixed it for me on Debian.
sudo apt-get install fonts-noto-color-emoji fc-cache -f -v
Afterwards restart Chrome and enjoy the colorful emoji 🥳
Instead of using AI tools to tear people down, what if we used them to uplift others? Introducing Praise my GitHub profile:
Xe Iaso made this cool tool, which creates happiness ❤️
Added the HTML5 Validator GitHub Action to the repo of my blog.
It runs after the Jekyll site generation step (and before the deploy-to-server step) to catch invalid HTML syntax.
It is configured to validate all generated pages, and promptly surfaced some invalid HTML.
This was rather surprising, as I manually did run the validation for the blog pages not too long ago.
Turns out when you have a blog with 20 year old comments, then some of them have HTML from 20 years ago which is no longer valid nowadays 🤷
After a round of fixing old comments, all HTML validaton errors are now gone ✅
And future invalid HTML syntax will be alerted upon before it ends up on the Internet 😎
With Git it is possible to push only certain local commits to a remote repository.
This can be done with the following git push command, which pushes all commits up to commit to the branch remote branch in the remote repo repository:
git push <repository> <commit>:<remote branch>
For example the following pushes all except for the latest local commit to the main branch in the origin remote repo:
git push origin HEAD~1:main
Following up on yesterday's post about the Website Carbon Calculator, I saw that there is also the option to add a Website Carbon Badge.
Quickly this badge was added to the About page.
To make it more accurate and avoid hitting their API every time someone loads the About page, I made some changes to the provided code:
While surfing around, stumbled upon this cool tool which allows to calculate the carbon footprint of a website: Website Carbon Calculator.
After having it analyze my blog, I was very pleased to see the resulting A+ carbon rating 🎉
The tool reports that every time someone loads my blog, 0.01g of CO2 is produced.
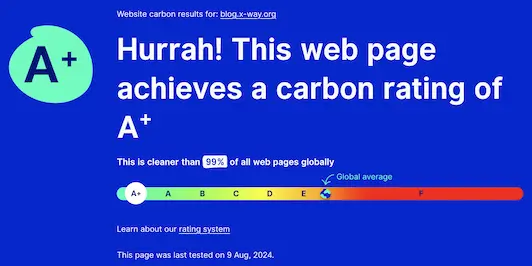
I suspect that this value and rating might fluctuate based on how many images or videos appear in the last 10 posts shown on the front page of the blog.
The results page, also allows to calculate how much CO2 would be produced in a year based on 10, 100, 1000, … monthly page views and compares this to everyday tasks.
Having 1000 monthly page views on this blog over a whole year, theoretically produces as much CO2 as boiling water for 16 cups of tea 🍵
(via)
As the CSS code of the blog has been growing lately, I moved it from inline <style> definition to a dedicated css/plain.css file.
With caching headers configured to cache *.css files for 10 days, this brings the problem that browsers need to be instructed to load a new version whenever the content of the file changes.
Removing the caching headers is not desired (as we want to leverage caching and the file does not change so often after all).
Thus I came up with a different workaround:
We add a query parameter to the <link> element that references the CSS file, and then change this query parameter whenever the file content changes.
This way browsers will load the newest version and keep it cached until a newer version is available.
To achieve this, the following script is used to compute and inject the query parameter into the layout template before running Jekyll to generate the HTML pages for the blog:
#!/bin/bash CSSFILES="css/plain.css" TARGETFILE="_layouts/x-log.html" for CSS in $CSSFILES ; do sum=$(sha256sum "$CSS"|head -c 6) sed -i -e "s_${CSS}_&?${sum}_g" $TARGETFILE done
It performs the following change in the template file.
Before:
... <link rel="stylesheet" href="https://blog.x-way.org/css/plain.css" type="text/css" media="all"> ...
After:
... <link rel="stylesheet" href="https://blog.x-way.org/css/plain.css?f00bad" type="text/css" media="all"> ...
As the computed query parameter is based on the hashsum of the content of the CSS file, it only changes when the CSS file is changed, thus ensuring caching still works as expected.
To make emoji stand out better in the text, I applied a trick from Terence Eden to increase their size with CSS and no extra HTML.
It consists of defining a custom font which only applies to the unicode codepoints of emoji and leverages the size-adjust property to draw them larger.
@font-face { font-family: "myemoji"; src: local('Apple Color Emoji'), local('Android Emoji'), local('Segoe UI Emoji'), local('Noto Color Emoji'), local(EmojiSymbols), local(Symbola); unicode-range: U+231A-231B, U+23E9-23EC, U+23F0, U+23F3, U+25FD-25FE, U+2614-2615, U+2648-2653, U+267F, U+2693, U+26A1, U+26AA-26AB, U+26BD-26BE, U+26C4-26C5, U+26CE, U+26D4, U+26EA, U+26F2-26F3, U+26F5, U+26FA, U+26FD, U+2705, U+270A-270B, U+2728, U+274C, U+274E, U+2753-2755, U+2757, U+2795-2797, U+27B0, U+27BF, U+2B1B-2B1C, U+2B50, U+2B55, U+FE0F, U+1F004, U+1F0CF, U+1F18E, U+1F191-1F19A, U+1F1E6-1F1FF, U+1F201, U+1F21A, U+1F22F, U+1F232-1F236, U+1F238-1F23A, U+1F250-1F251, U+1F300-1F320, U+1F32D-1F335, U+1F337-1F393, U+1F3A0-1F3CA, U+1F3CF-1F3D3, U+1F3E0-1F3F0, U+1F3F4, U+1F3F8-1F43E, U+1F440, U+1F442-1F4FC, U+1F4FF-1F53D, U+1F54B-1F567, U+1F57A, U+1F595-1F596, U+1F5A4, U+1F5FB-1F64F, U+1F680-1F6CC, U+1F6D0-1F6D2, U+1F6D5-1F6D7, U+1F6DC-1F6DF, U+1F6EB-1F6EC, U+1F6F4-1F6FC, U+1F7E0-1F7EB, U+1F7F0, U+1F90C-1F93A, U+1F93C-1F945, U+1F947-1FA7C, U+1FA80-1FAC5, U+1FACE-1FADB, U+1FAE0-1FAE8, U+1FAF0-1FAF8; size-adjust: 120%; }
By adding the custom font as first option in the font-family directive for body text, it will be applied to the emoji and all other characters will use the existing font as fallback.
body { font-family: "myemoji", Verdana, sans-serif; }
The outcome is nicely visible on posts such as Fifty Things you can do with a Software Defined Radio 📻, Puppet updated! and The High-Risk Refactoring 🍹😎
The following command outputs the current time formatted according to ISO 8601 and RFC3339. It can be used for example in JSON/HTML.
date -u '+%FT%TZ'
2024-08-03T14:41:47Z
Useful trick posted by Volker Weber: enable the Orientation Lock by default and use Automation Shortcuts to toggle it when Apps such as Photos or YouTube are opened/closed.
This allows to view pictures/videos in landscape mode while other Apps remain in portrait mode, all without having to manually toggle the Orientation Lock.
Discovered today that Puppet arrays have a built-in flatten method (which is actually provided by the underlying Ruby array).
This can make dealing with potentially nested arrays in ERB templates much easier.
The following example is from the ERB documentation:
# Peers <% [@peers].flatten.each do |peer| -%> peer <%= peer %> <% end -%>
This allows for nice flexibility as @peers can now be either a single value, an array, or a nested array and all are handled in the same way without needing to write complicated if/else statements.
Let's Encrypt announced that it intends to stop supporting OCSP, which means that OCSP is basically dead now.
OCSP stapling on my server has been enabled since 2012.
With the prospect of it no longer working in the future, I've disabled it again in the nginx configuration.
# aj, 05.11.2012, OCSP stapling (for testing see http://unmitigatedrisk.com/?p=100)
# aj, 25.07.2024, turn it off again, as letsencrypt will disable it: https://letsencrypt.org/2024/07/23/replacing-ocsp-with-crls.html
# ssl_stapling on;
There are some new blog directory sites popping up again. Nice way to discover niche personal sites outside of the big platforms.
Less: a Survival Guide is a concise post from zck.org demystifying the features of less.
My two main takeaways were:
1. Configuring less via the LESS environment variable.
The following enables markers and highlighting for search & jump actions, colored output and raw display of terminal escape sequences.
export LESS="-J -W --use-color -R"
2. Jumping to the start and end of a document with g and G.
I already used / for searching, but had always struggled to go back to the beginning of a document.

While browsing for something unrelated, I came about this wonderful Lego set called 'Tales of the Space Age'.
It was originally created by a fan designer through the Lego Ideas program and turned into this amazing looking Lego set.
I like the depiction of the space themed science fiction worlds very much, especially the beautiful color gradients giving each world a unique atmosphere.
The provided building instructions booklet builds on top of this with illustrations enhancing the views of these worlds.
Looking at these four panels with the nice space themed color gradients inspired me to rebuild them in CSS.
First I toyed around with one and then built the other three.
The outcome of this is now visible on andreasjaggi.ch where I replaced the previous entry page with the four color gradients.
The previous version is still available on andreas-jaggi.ch as I couldn't decide yet to retire it, so will be keeping both for now :-)
Recently I added a Generator section to the about page with minimal information about how this page was generated.
As part of this it now also shows the version of the Jekyll software that was used to generate everything.
Surprisingly there seems to be no built-in way to get the version as a template tag.
Thus I wrote this mini-plugin to provide such a {% jekyll_version %} tag that can be used to get the version of Jekyll while it is processing the pages.
To use it with your own Jekyll, simply store the below code in a _plugins/jekyll_version_plugin.rb file.
# frozen_string_literal: true module Jekyll class VersionTag < Liquid::Tag def render(context) Jekyll::VERSION end end end Liquid::Template.register_tag("jekyll_version", Jekyll::VersionTag)
After last weeks work on the statistics page, I was still not completely happy with how it renders in text-only browsers.
Thus the idea of adding <th> headers to the two rows of numbers.
This turned out quite well and helped to make things more clear as you can see in this screenshot.
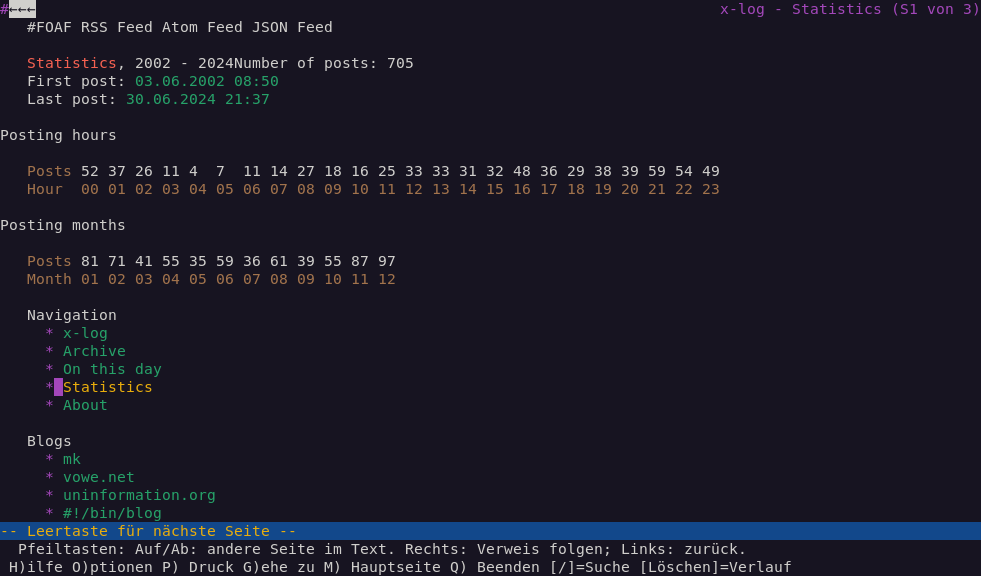
I initially wanted to use the :first-child selector to hide these additional table headers in graphical web browsers.
But didn't get it right with the first try, so the header still showed.
This actually didn't look that bad, and so I decided to keep the headers visible and styled them nicely so they integrate well with the rest of the statistics table.
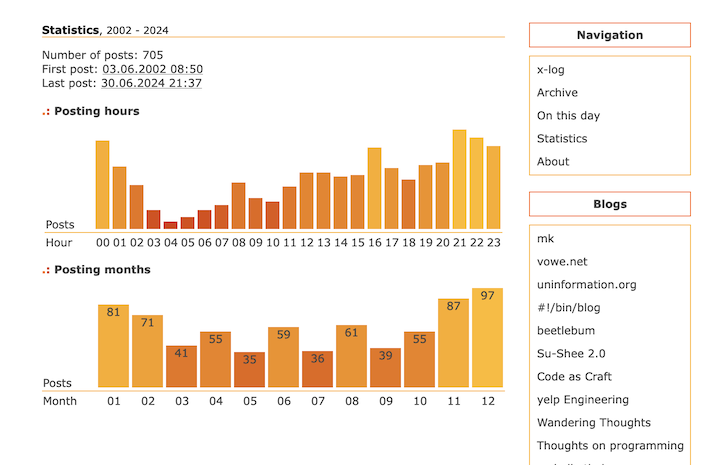
This is how the statistics page now looks in a graphical web browser.
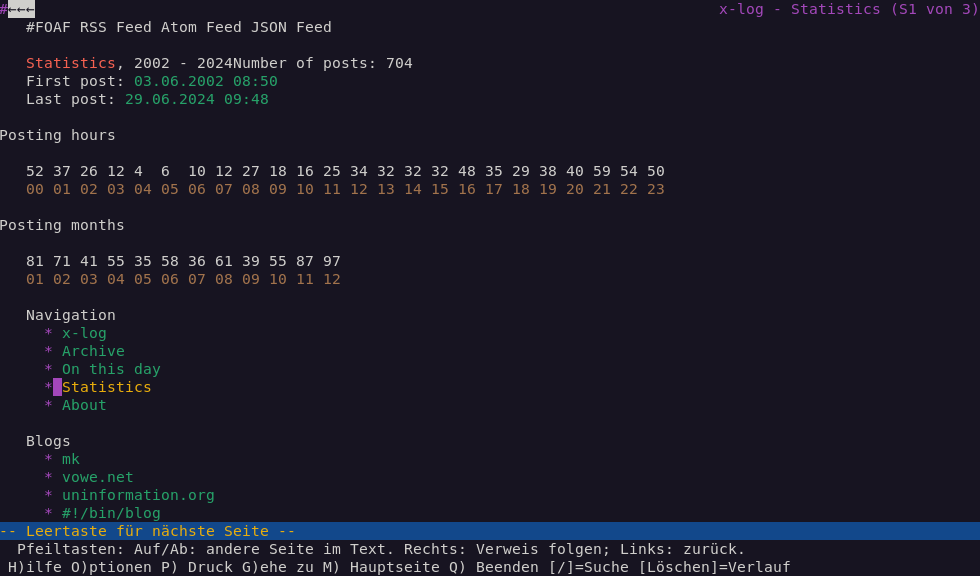
Some time ago I read this article from Dan Q about testing your website in a text-only browser (Lynx, which is the oldest web browser still being maintained, started in 1992).
Surfing through my blog with Lynx, I was positively surprised in how well the content and structure was presented.
Seems like the modernization and simplification efforts of the HTML code behind the scenes paid off well.
The statistics page though was not really usable, it was displayed as a random soup of numbers due to the usage of unstructured <div> tags for the elements of the visual graphs.
To fix this I reverted back to using <table> tags to structure the data.
This way the layout degrades gracefully in text-only browsers and provides a minimally structured representation of the data.
And I applied the newly learned CSS skills (linear-gradient backgrounds) to achieve the same visual graph as beforehand when opening the page in a regular browser.
While looking at my 404s the top one for the blog was /.well-known/traffic-advice.
This is part of the traffic advice mechanism to control traffic from prefetch proxies (and based on my current access logs, seems only used by the Chrome Privacy Preserving Prefetch Proxy).
The traffic advice mechanism is specified in the document here.
It can be used to reduce the number of requests coming from prefetch proxies.
To get rid of the 404s and provide support for the traffic advice mechanism, I use the following snippet in my nginx config.
It allows all requests from prefetch proxies (as currently I see no need to limit them).
# Private Prefetch Proxy # https://developer.chrome.com/blog/private-prefetch-proxy/ location /.well-known/traffic-advice { types { } default_type "application/trafficadvice+json"; return 200 '[{"user_agent":"prefetch-proxy","fraction":1.0}]'; }
After the recent addition of custom Web Components, the usual feed validators were a bit less happy about my RSS and Atom feeds.
They always marked my feeds as valid, but usually had some recommendations to improve interoperability with the widest range of feed readers.
In particular having non-HTML5 elements does not help with interoperability. Which makes sense as there is no real place in the XML of the feeds to reference the needed JavaScript for rendering the Web Components.
Besides stripping away the <youtube-vimeo-embed> tags and replacing them with a link to the video, I took this opportunity to cleanup some other 'Altlasten' (legacy tech depts).
A lot of time was spent trying to get my head around various encodings/escapings of special characters. When the blog started in 2002, UTF-8 was not adopted yet and all special characters needed to be written as HTML entities.
And what didn't help is that I somehow had a text-only part in my RSS file which tried to deliver a version of my posts without any HTML (but failed to do so properly as it only had the tags stripped away but did not revert all the HTML character encodings.
Of course the various resulting & characters nicely clash with XML encoding).
There were some other oddities from the past, such as empty post titles and HTML tags inside titles.
I ended up cleaning up most of this and got rid of the text-only representation and corresponding encoding/escaping problems. (using <![CDATA[ and ]]> with the HTML content inside makes life so much easier)
The still remaing recommendations to improve are about relative links and <script> tags.
The relative links are all due to my replacing of dead and non-archived link destinations with a single #. So they are more a 'false postive' than a real problem, the links are dead either way.
The <script> tags are more problematic, as they result from my embedding of GitHub Gists in posts. The code in the Gists is loaded, rendered and nicely highlighted with color by the script, thus not easy to replicate in a feed.
Probably the best approach for the Gists would be to find a way to properly include the content into the posts. So that it is rendered nicely when viewed in a browser, and has a meaningful text-only fallback in the feeds.
Would make sense to self-hosts these anyways. Next rainy weekend project there you are :-)
![]()
![]()

Amazing food art by sibatable.
Besides the Instagram page and the ohou.se page check out the articles from Tapas and My Modern Met for more infos about the artist.
(via)
Out of curiosity I wanted to know how much of my Internet traffic uses IPv6 vs the legacy IPv4.
There is no out-of-the-box graph for this in MikroTik.
Several forum and Stack Overflow posts suggest using ratelimiting queues with their graphing feature to collect this data.
After experimenting a bit, I ended up with the following configuration which creates two queues to collect the traffic data.
Important to know, traffic flows on a first-match basis through the queues. Thus the trick of having first the queue matching IPv6 traffic and then the queue matching all the remaining traffic.
Also, I use 10G as 'unreachable' traffic limit to avoid any traffic being ratelimited. This works well for my 1Gbit/s setup, but will need to be adjusted if you have a higher bandwidth.
/queue simple add limit-at=10G/10G max-limit=10G/10G name=v6-traffic queue=ethernet-default/ethernet-default target=2000::/3 total-queue=ethernet-default /queue simple add limit-at=10G/10G max-limit=10G/10G name=v4-traffic queue=ethernet-default/ethernet-default target="" total-queue=ethernet-default
Having the queues in place for a couple days results in the following graphs:
IPv6 Traffic
IPv4 Traffic
Happy to see that a large majority of my traffic uses IPv6 :-)
After the recent integration of Web Components in the blog, I made yet another stab at using some modern technologies.
This time inspired by the Ten years of A Single Div article, my focus was on the linear-gradient() and radial-gradient() CSS properties.
They can be combined to draw almost arbitrary shapes with pure CSS.
I used this to replace all graphics on andreas-jaggi.ch with CSS, while keeping the layout and functionality identical to the original 2005 version.
In the process of this, also some additional modern CSS features were used:
var() to simplify repeating CSS code.
animation/@keyframes to add a little fade-in effect on the hover text.
The recent article from Adrian Roselli explaining how to write a Web Component for YouTube and Vimeo videos, triggered me to finally adopt the Web Components technology for my blog.
Additionally there is Markus using Web Components for his blog since quite some time, which gave me confidence.
Implementing Web Components was now not only for the sake of learning about the technology, but also to address some longstanding painpoints I had with my embedded videos.
In particular did I not like that each embedded video triggered the loading of a plethora of third-party scripts and styles only to render the thumbnail image. And additionally this leaked tracking/cookie information to the video hosters (yes, I was using www.youtube-nocookie.com to reduce this as far as possible, but could not eliminate it completely).
Thus I added a <youtube-vimeo-embed> Web Component and changed all my embedded YouTube and Vimeo videos to use it.
My implementation is almost a 1:1 copy of the code provided by Adrian, with some minor adaptions (such as hiding the original link when the video iframe can be rendered and always enabling fullscreen mode in videos).
I'm quite happy with the outcome, as it provides some new benefits:
Except for the thumbnail image, no other third-party resources are loaded until someone clicks on the play button.
When JavaScript or Web Components are not supported by a browser, it gracefuly falls back to a simple link to the video.
Loading speed of the whole page improved quite a bit, as videos are only loaded on demand.
It always uses www.youtube-nocookie.com and third-party scripts are only loaded if someone explicitly clicks on the play button of a video :-)
While browsing posts from the past on the On this day page, I saw the one about blog.gs from 2002.
Turns out the blog.gs ping mechanism is still working in exactly the same way after all these years (nowadays operated by Automattic).
As I don't run my blog with PHP anymore, I added the following step at the end of my deploy script.
It uses curl to peform the XML-RPC call of the weblogUpdates.extendedPing API with the parameters for my weblog.
curl -X POST -v ping.blo.gs -H 'content-type: text/xml' --data '<?xml version="1.0"?><methodCall><methodName>weblogUpdates.extendedPing</methodName><params><param><value>x-log</value></param><param><value>https://blog.x-way.org/</value></param><param><value></value></param><param><value>https://blog.x-way.org/rss.xml</value></param></params></methodCall>'
Michael W Lucas is running a Kickstarter campaign to fund writing of book providing the knowledge to run your own mail server.
As I'm running my own mail server (coincidently with some of the tools that will be discussed in the book: Debian, Postfix, Dovecot), I do sympathize with this initiative and would recommend to support the campaign.
As seen all over the place, adding udm=14 to the URL of a Google search makes the result display less crappy (no ads, no AI suggestions to eat rocks or put glue on pizza, …).
The search results themselves of course are not really getting better with this, but at least the search experience is less annoying.
For the Desktop edition of Firefox you will need to use the udm14 extension to add the udm=14 parameter by default to your search bar.
For other browsers it should be enough to modify the settings of the search URL used and add the parameter (something like https://www.google.com/search?q=%s&udm=14).
Or even better, do use an alternative search engine :-)
In the Recent Docker BuildKit Features You're Missing Out On article, Martin Heinz lists some of the new features that have been added to Docker with the BuildKit introduction.
My favorite one is the debugger for failed build steps of a container:
export BUILDX_EXPERIMENTAL=1 docker buildx debug --invoke /bin/sh --on=error build .
Migrations are not something you can do rarely, or put off, or avoid; not if you are a growing company. Migrations are an ordinary fact of life.
Doing them swiftly, efficiently, and -- most of all -- *completely* is one of the most critical skills you can develop as a team.
— Charity Majors (via)
Brings back some faint memories of young me playing around with FrontPage (wondering why the preview rendering of an animated fullscreen background of a burning fire is making the computer go slow…)
(via)
In his 20 year anniversary post, Terence Eden explains how he uses the "On This Day" feature of his blog every morning to look back on what he was writing on this day in previous years.
Finding this very inspiring, I decided to add a similar feature to my blog.
As my blog is built with Jekyll as static pages, some plain old JavaScript was needed to surface the posts of this day without having to rebuild the page daily.
And here we have now the On this day page :-)
The warm temperatures around here made me change the blog theme back to the warm colors ☀️
Basically it's a revert of the winter layout changes from beginning of the year, while keeping all the HTML modernizations done afterwards :-)
We're back on the original 2002 layout (with modern HTML), for those trying to keep score. Enjoy!
What if Marie Kondo would become a software engineer?
Ben Buchanan did run a parody account on this topic and has archived the posts on his site.
There are some gems :-)
To choose what to keep and what to throw away, take each dependency in one's manifest and ask: "Does this spark joy?" If it does, keep it. If not, remove it from your codebase.
We should be choosing what to
.gitkeep, not what we want to.gitignore
Cruft has only two possible causes: too much effort is required to refactor or it is unclear where things belong.

"If you don't fit... Maybe you haven't found the right puzzle." — Admiral Wonderboat (via)
Due to a hardware failure I had to replace one of my computers (switching from a 2015 Intel NUC to a Dell OptiPlex Micro 7010).
After moving the disk to the new system, it refused to boot (claimed that no bootable drive was available).
Turns out that the new system only supports UEFI booting and the existing disk was setup for 'legacy'/CSM boot.
I used the following steps to convert the existing disk to UEFI boot (while keeping all data on it available).
They are inspired by the excellent Switch Debian from legacy to UEFI boot mode guide from Jens Getreu.
/dev/nvme0n1 in my case)# gdisk /dev/nvme0n1 r recovery and transformation options (experts only) f load MBR and build fresh GPT from it w write table to disk and exit
# apt-get install gparted
# gparted /dev/nvme0n1Resize an existing partition to create space (does not need to be at the beginning of the disk, I used the swap partition).
fat32 and flag it bootable.EF00 for the efi partition and EF02 for the Grub2 partition):
# gdisk /dev/nvme0n1 p print the partition table t change a partition's type code t change a partition's type code w write table to disk and exit
# mount -t ext4 /dev/nvme0n1p1 /mnt # mkdir /mnt/boot/efi # mount /dev/nvme0n1p2 /mnt/boot/efi # mount --bind /sys /mnt/sys # mount --bind /proc /mnt/proc # mount --bind /dev /mnt/dev # mount --bind /dev/pts /mnt/dev/pts # cp /etc/resolv.conf /mnt/etc/resolv.conf # chroot /mnt
# ls -lisa /dev/disk/by-uuidIdentify the UUID of the EFI partition (usually in the format
XXXX-XXXX) and add a corresponding line to /etc/fstab:
# echo "UUID=XXXX-XXXX /boot/efi vfat defaults 0 2" >> /etc/fstab
# apt-get remove grub-pc # apt-get install grub-efi
# grub-install /dev/nvme0n1
# exit # reboot
/EFI/debian/grubx64.efi) in the UEFI BIOS and make it the default :-)Needed to create a bootable Debian USB stick for some maintenance on one of my computers.
Here are the steps so I won't have to search for them the next time :-)
sudo diskutil list
sudo diskutil unmountdisk /dev/diskX
sudo dd if=./debian-live-12.5.0-amd64-standard.iso of=/dev/diskX bs=1m
Tiny Fragments is a fun little puzzle game made by Daniel Moreno (via)

Interesting article explaining how to test HTML with visual CSS highlighting: Testing HTML with modern CSS (via)
In the Print HTTP Headers and Pretty-Print JSON Response post, Susam Pal shows a nice trick to pretty-print JSON output with jq from curl while also showing the HTTP response headers (using stderr):
curl -sSD /dev/stderr https://some-URL-returning-JSON | jq .
Modern Git Commands and Features You Should Be Using — a short article from Martin Heinz about some new-ish (>2018) features in Git, that 'can make your life so much easier'.
TL;DR:
git switch <branchname>git restore --staged <somefile>git restore --source <commit> <somefile>git sparse-checkoutgit worktreegit bisectSimilar post from five years ago: More productive Git
This post from Rachel, reminded me of my own struggle with a Raspberry Pi and time (and yes, I did run into the same DNSSEC problem).
I first tried a RTC shield, but this didn't fully solve all problems.
My workaround in the end is to use two fixed IP addresses in ntp.conf in additon to the usual pool servers.
Thanks ${previous employer} for not changing the IPs of your public NTP servers so far :-)
As hinted at in my previous post, Solnet is delivering native IPv6 Internet again.
Shortly after 23h on March 26th there was a brief interruption of the Internet uplink and afterwards my router started receiving an IPv6 address again.
My support ticket with Solnet is still unanswered, but at least IPv6 is back :-)
While browsing through the archives I stumbled upon the SixSpotting post from 2014.
Turns out the game is still working and after some failed attempts I managed to remember my account name and log in.
I guess it must look quite strange to see a burst of new checkins after almost 10 years 😄

After following a couple links from the article linked in the previous blogpost, I ended up reading the Website Component Checklist from Mike Sass.
It provides again a lot of inspiration for things to add to my weblog.
What intrigued me today on the list was humans.txt, which is an initiative for knowing the people behing a website.
Thus I've now added the following humans.txt.
100 more things you can do with your personal website — a follow-up to the popular post from last month :-)

Dog Poo Golf, a Wii Sports Golf-style browser game (with the music!) where you fling dog poop bags into a garbage can. 🐶💩⛳ (via kottke.org)
Yay! Successfully updated my Puppet Server setup from 5.3.7 to 8.4.0 🎉
It was quite a step (5.3.7 was released in January 2019) and as expected 3 major version bumps came with a couple changes.
I opted to re-create the PuppetDB and CA stores from scratch (to avoid having to migrate 5 years of data schema changes, and the CA cert is now also valid for a couple more years again).
To make the old manifests and modules work with the new versions, quite some effort was needed. This included rewriting some no longer maintained modules to use newer stdlib and concat libraries, updating a couple modules from the puppet forge (with the bonus that my puppet server runs airgapped and I had to use the download-tar-copy-extract way to install them) and fixing no longer valid syntax here and there in my custom manifests. Overall I spent about 5 hours on it (and have now a recurring reminder to update puppet more often to make this process less painful).
Helpful as usual were the resources from Vox Pupuli, in particular the Puppet Server and PuppetDB Docker images and the CRAFTY repo which contains a fully self-contained Docker Compose setup very similar to what I'm running.
Some commands that came in handy:
puppet config print ssldir --section agent
Returns the path of the TLS config folder on the client. Useful during a CA change (where you rm -rf the whole folder and then request a new TLS certificate).
puppet agent -t --noop
Dry-run the changes on the client (it does request a new TLS cert though!). Shows a nice diff of the changes it would do to files, helpful to validate that a manifest still behaves the same in the new version.
Brendan Gregg posted the following list of 'crisis tools' which you should install on your Linux servers by default (so they are available when an incident happens).
| Package | Provides | Notes |
|---|---|---|
| procps | ps(1), vmstat(8), uptime(1), top(1) | basic stats |
| util-linux | dmesg(1), lsblk(1), lscpu(1) | system log, device info |
| sysstat | iostat(1), mpstat(1), pidstat(1), sar(1) | device stats |
| iproute2 | ip(8), ss(8), nstat(8), tc(8) | preferred net tools |
| numactl | numastat(8) | NUMA stats |
| tcpdump | tcpdump(8) | Network sniffer |
| linux-tools-common linux-tools-$(uname -r) | perf(1), turbostat(8) | profiler and PMU stats |
| bpfcc-tools (bcc) | opensnoop(8), execsnoop(8), runqlat(8), softirqs(8), hardirqs(8), ext4slower(8), ext4dist(8), biotop(8), biosnoop(8), biolatency(8), tcptop(8), tcplife(8), trace(8), argdist(8), funccount(8), profile(8), etc. | canned eBPF tools[1] |
| bpftrace | bpftrace, basic versions of opensnoop(8), execsnoop(8), runqlat(8), biosnoop(8), etc. | eBPF scripting[1] |
| trace-cmd | trace-cmd(1) | Ftrace CLI |
| nicstat | nicstat(1) | net device stats |
| ethtool | ethtool(8) | net device info |
| tiptop | tiptop(1) | PMU/PMC top |
| cpuid | cpuid(1) | CPU details |
| msr-tools | rdmsr(8), wrmsr(8) | CPU digging |
At the recent HB9TF AGM fellow radio amateur HB9GVM gave an introductory presentation about AREDN.
Motivated by this, I ordered a MikroTik hAP ac lite and installed the AREDN firmware on it.
The following are my notes of the installation process.
brew install dnsmasq
mkdir tftp-root cp $HOME/Downloads/aredn-3.23.12.0-ath79-mikrotik-mikrotik_routerboard-952ui-5ac2nd-initramfs-kernel.bin tftp-root/rb.elf
ifconfig en6 # use to check that IP is configured sudo dnsmasq -i en6 -u $(whoami) --log-dhcp --bootp-dynamic --dhcp-range=192.168.1.100,192.168.1.200 -d -p0 -K --dhcp-boot=rb.elf --enable-tftp --tftp-root=$(pwd)/tftp-root/
ping 192.168.1.1
http://192.168.1.1/cgi-bin/admin (Username is root and password is hsmm).http://192.168.1.1 – congratulations, you now have a freshly installed (and not yet configured) AREDN node :-)Fifty Things you can do with a Software Defined Radio 📻 — some cool SDR things to do (have done already some of them and more with my HB9TF friends :-)
(via)
Also using this post to introduce a new category: Radio
Which will serve as a container for radio/HAM/Wireless related content.
100 things you can do on your personal website — lots of ideas/inspirations also for this blog :-)
(via)
After nicely delivering native IPv6 connectivity for 3 years, my Internet provider Solnet made some changes in their backbone config on January 31st which broke their IPv6 setup.
Unfortunately escalating with their support did not bear any fruits so far (current state: they no longer respond on the support ticket…).
Thus change of plans, tunnelbroker.net (Hurricane Electric) to the rescue.
Took about 10 minutes to set everything up and now I'm enjoying IPv6 connectivity again (although with a reduced end-to-end MTU due to the 6in4 encapsulation).
Guess I'll have to look for a different Internet provider again.
Especially annoying is that I renewed the yearly plan with Solnet only a couple weeks ago, so will be stuck without native IPv6 connectivity for the next 11 months :-(
In the The High-Risk Refactoring article there is this concise Addressing Risk checklist to keep in mind when refactoring.
During past refactorings (also low-risk ones) I often used almost the same guidelines to help me and can only recommend you to do the same:
✅ Define constraints. How far should I go.
✅ Isolate improvements from features. Do not apply them simultaneously.
✅ Write extensive tests. Higher level (integration) with fewer implementation details. They should run alongside changes.
✅ Have a visual confirmation. Open the browser.❌ Do not skip tests. Don't be lazy.
❌ Do not rely too much on code reviews and QA. Humans make mistakes.
❌ Do not mix expensive cleanups with other changes. But do that for small improvements.
(via)
Please Blog — a plea for less Big Web and more Small Web and an encouraging article to write your own blog. It also touches on the part about writing on your own domain (so to keep your content yours and not be at risk of a third-party commercial 'social' service going away).
Don’t wait for the Pulitzer piece. Tell me about your ride to work, about your food, what flavor ice cream you like. Let me be part of happiness and sadness. Show me, that there is a human being out there that, agree or not, I can relate to. Because without it, we are just actors in a sea of actors, marketing, proselytizing, advocating, and threatening towards each other in an always vicious circle of striving for a relevance that only buys us more marketing, more proselytizing, more advocating, and more threats.
(discovered via Thomas Gigold)
Added and ads.txt file to the blog. The idea is to avoid that someone can sell fake advertisment space for this blog.
As I don't use any advertisment here the content of the file is pretty basic:
contact=https://blog.x-way.org/about.html
ldapauth is a Node.js script which I have been using for the last 12+ years mostly unchanged.
It started its life in a LXC container, eventually was moved to a Docker container and recently ended up in its own repository on GitHub.
The functionality it provides is not extraordinary, but helped to bridge a gap where no other product was available.
It talks LDAP one one side (although limited to handle user lookup requests) and on the other side connects to a MongoDB database where the information is stored.
It emerged out of the desire to have an easy way to manage individual user accounts for my home WiFi. I already had MongoDB running for some other personal project and simply added the list of users there (including the UI for managing them).
Thus the missing part was to get the WiFi accesspoint to lookup user accounts in MongoDB.
Of course WiFi accesspoints do not directly talk MongoDB, but rather some other protocol like RADIUS.
A freeradius server was quickly setup, but still couldn't talk to MongoDB at the time. Thus comes in ldapauth, which takes LDAP queries from freeradius and turns them into MongoDB lookups so that in the end the WiFi accesspoint receives the user accounts :-)
Not sure if this is particularly useful for anyone else, but at least here it did provide good services (and continues to do so).
Current score is that it has survived three different WiFi accesspoints and has been running on 5 different servers over the time.
Some vibes from Australia ❤
Some time ago I used an online tool to generate some QR codes with a contact URL so I can put them on my luggage.
Now I got a new bag and need a new QR code for it. As I don't remember the online tool I used years ago, I decided to write my own tool.
Thus say hello to qr-bag. It's a commandline tool written in Go to generate QR codes for URLs with a little logo in the middle.
The code for it is mostly a wrapper around the go-qrcode library which does all the heavy lifting.

Just discovered the text-decoration-color CSS property and added it to the style on the blog:
a:hover {color: #454545; text-decoration: underline; text-decoration-color: #26C4FF;}
This causes that when you hover over a link in a post, the underline is not in the same boring gray as the text but lights up in a nice color :-)
(not to be confused with the hacky colored underlines in the righthand navigation bar, where I use a colored border-bottom to achieve a similar effect since 2002)
It's time again to do some cleanup of my blogroll before the links start to turn into 404 errors :-)
Removed:
Following in the trend of replacing tables, I've revived the old statistics page.
Now using less markup as it is built with <div> and CSS only (the display: inline-block; property was particularly helpful).
(the Jekyll/Liquid templating to generate the data for it looks quite horrific though…)
Over the last couple weeks I slowly replaced the various <table>-based layout elements of the blog with more modern HTML elements.
And finally this afternoon the work was completed with the last <table> element gone.
Visually there should be almost no differences, but in case something looks strange just let me know :-)
(and yes, style-wise everything is still using the pixel-based layout from 2002, one day this might change as well…)
To provide basic dark mode support for the blog, I added the following lines of CSS:
@media (prefers-color-scheme: dark) { html { filter: invert(1) hue-rotate(180deg); } img, video, iframe { filter: invert(1) hue-rotate(180deg); } }
If the browser/OS has dark mode enabled it will invert the colors and rotate the hue to achieve the dark mode effect.
The whole operation is applied a second time on images, videos and frames to avoid that they have their colors distorted.
You can get a preview by using the developer tools of your browser to enable dark mode :-)
The code is inspired by the post here, and then extended to provide a CSS-only solution by leveraging the color-scheme CSS property.
Some very fine Drum and bass. Recently got to experience two of them live (Sub Focus & 1991), and have plans to see Dimension next :-)
Especially like the little The Prodigy mixin starting at 1:04:30 🥳
As mentioned before, I'm a supporter of the Cool URIs don't change approach.
Thus I try to keep all the URLs of this blog working (or at least make them redirect to the new place where the content is located).
Not always an easy task with old domains and multiple blogging engines accumulated over the years.
To help me with that (and ensure I don't break anything when updating a 10+ year old mod_rewrite config) I created a short Bash script to test the redirect behavior.
It contains a list of URLs and their expected redirect target, goes through them with curl and checks that the correct Location: header is returned.
As it might be useful for others in similar situations, the script can be found here.
I miss human curation — Where are my internet friends? And where are their weird blogs? (via)
While adding some new alias functionality to my setup, it repeatedly failed with an error similar to this, despite my configuration changes:
Recipient address rejected: unverified address: host XXX[XXX] said: 550 5.1.1 <foo@bar.com> User doesn't exist: foo@bar.com (in reply to RCPT TO command);
Turns out that the negative verification result is cached and the cache is not reset during a reload/restart of postfix.
Thus it must be cleared manually like this:
/etc/init.d/postfix stop rm /var/lib/postfix/verify_cache.db /etc/init.d/postfix start
After switching the colors of the design, I kept the momentum and continued working on the HTML of the blog.
It took couple iterations of multiple hours, but now it's done: the HTML source of this blog is valid HTML5!
Getting rid of the obsoleteness hidden in old blogentries dating back over 20 years also led to some interesting observations.
Back when moving from HTML 4.01 to XHTML 1.1, I remember spending some time to transform old <br> tags to <br />. And now for HTML5 I did the inverse and moved all <br /> tags back to <br> :-)
Also once more I'm very thankful for the work of the Internet Archive, which helped to recover images hosted on servers long gone (like URLs which already at the end of 2002 were no longer valid!).
Overall a lot of replacing no longer existing HTML tags and attributes with CSS definitions.
And there is virtually no change to the visual representation of the blog (which was the goal), so we still have the table-based layout with pixel-sized fonts as originally drafted in 2002.
Moving this to actually leverage modern HTML5 mechanisms and making it also more mobile friendly are tasks left for some future cold winter evenings :-)
![]()
Happy New Year! — Happy New Colors!
Winter is here (for a while already), time to change the colors of the blog.
To keep it in the nostalgic theme (the previous design was a repurpose of the inital design from 2002), I'm using the colors from the 'plain 2' winter layout (also from 2002).
Enjoy!
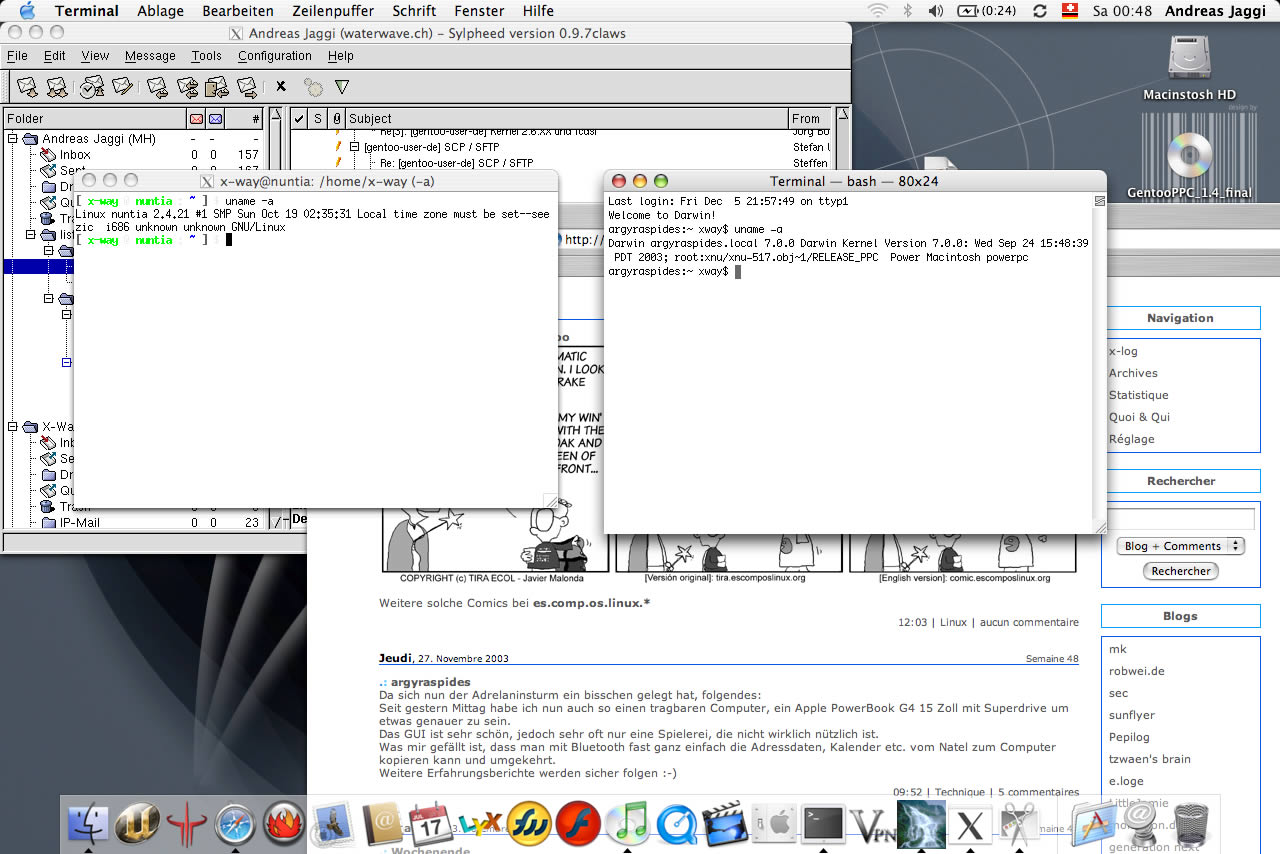{kind=link}
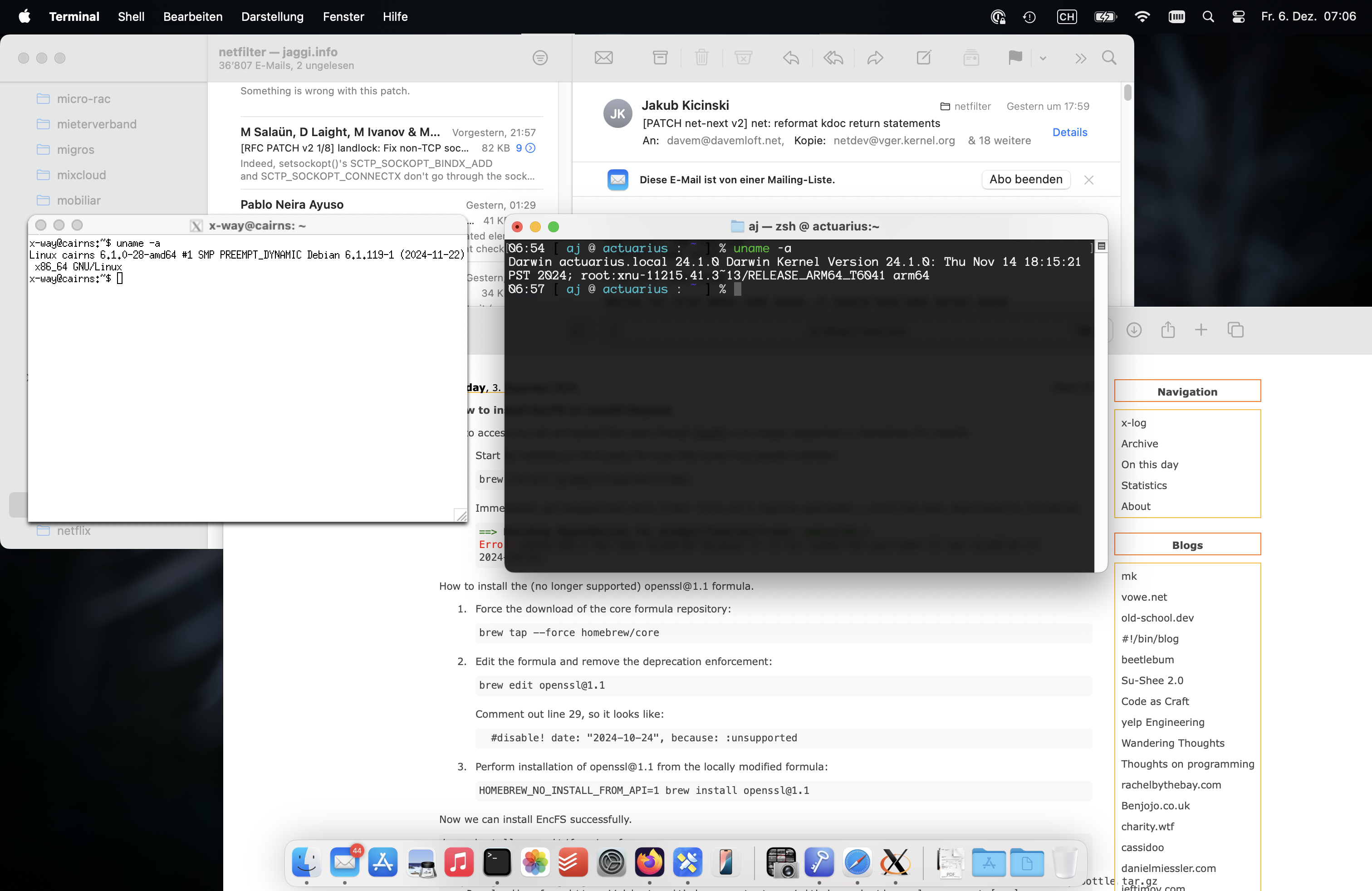{kind=link}